

{kind=link}
Last month at the Supercomputing 2024 conference, NVIDIA announced the availability of NVIDIA H200 NVL, the latest NVIDIA Hopper platform. Optimized for enterprise workloads, NVIDIA H200 NVL is a versatile platform that delivers accelerated performance for a wide range of AI and HPC applications. With its dual-slot PCIe form-factor and 600W TGP, the H200 NVL enables flexible configuration options for lower-power, air-cooled rack designs.
This post highlights H200 NVL innovations, our recommendations for the optimal server and networking configurations, and best practices for deploying at scale based on NVIDIA Enterprise Reference Architectures (Enterprise RAs).
NVIDIA H200 NVL accelerates AI for mainstream enterprise servers
NVIDIA H200 NVL is a platform for developing and deploying AI and HPC workloads, from AI agents for customer service and vulnerability identification to financial fraud detection, healthcare research, and seismic analysis. NVIDIA H200 NVL delivers AI acceleration for mainstream enterprise servers with up to 1.7x faster large language model (LLM) inference and 1.3x more performance on HPC applications over the H100 NVL. The innovations behind the H200 NVL are detailed in the following sections.
Upgraded memory
H200 NVL uses the same architecture as H100 NVL. But H200 NVL benefits from a massive upgrade in memory bandwidth and capacity with 141 GB HBM3e, an increase of 1.5x in capacity and 1.4x bandwidth, compared to H100 NVL.
These improvements mean bigger models can fit within a GPU, and data moves in and out of memory faster, resulting in higher throughput and more tokens per second. Because of the larger memory, you can also create larger multi-instance GPU (MIG) partitions to run multiple discrete workloads within the same GPU.
New NVLink capabilities
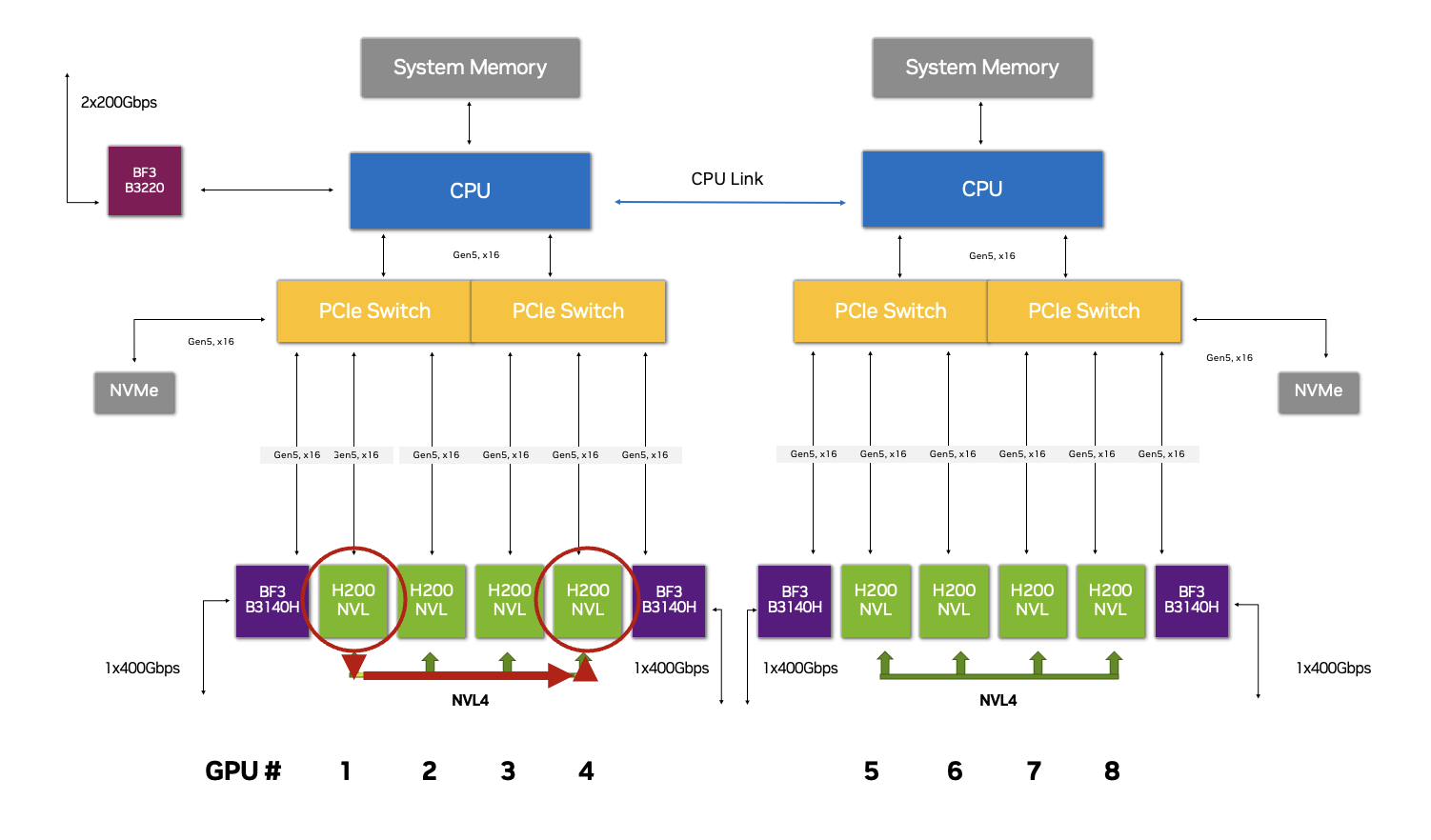
The H200 NVL introduces support for a new 4-way NVLink interconnect, delivering up to 1.8 TB/s of bandwidth and a combined 564 GB of HBM3e memory—providing 3x the memory compared to H100 NVL in a 2-way NVLink configuration.
Additionally, H200 NVL supports pairing with a 2-way NVLink bridge, delivering 900 GB/s of GPU-to-GPU interconnect bandwidth—a 50% increase compared to H100 NVL and 7x faster than PCIe Gen5.
| Feature | NVIDIA H100 NVL | NVIDIA H200 NVL | Improvement |
| Memory | 94 GB HBM3 | 141 GB HBM3e | 1.5x capacity |
| Memory Bandwidth | 3.35 TB/s | 4.8 TB/s | 1.4x faster |
| Max NVLink (BW) | 2-way (600 GB/s) | 4-way (1.8 TB/s) | 3x faster |
| Max Memory Pool | 188 GB | 564 GB | 3x larger |
NVIDIA AI Enterprise included
H200 NVL includes a 5-year subscription license for NVIDIA AI Enterprise. This cloud-native software platform delivers a comprehensive set of tools, frameworks, SDKs, and NVIDIA NIM microservices to streamline the development and deployment of enterprise-grade AI applications.
With access to NVIDIA NIM inference microservices and NVIDIA Blueprints, the power of NVIDIA AI Enterprise together with the H200 NVL provides the fastest pathway to build and operationalize custom AI applications while ensuring peak model performance.
Recommended configuration for H200 NVL
The NVIDIA Enterprise RA program recently expanded to include H200 NVL. Each NVIDIA Enterprise RA provides full-stack hardware and software recommendations for building high-performance, scalable, secure accelerated computing infrastructure and contains detailed guidance on optimal server, cluster, and network configurations for modern AI workloads.
At the core of each Enterprise RA is an optimized NVIDIA-Certified System server that follows a prescriptive design pattern to ensure optimal performance when deployed in a cluster environment. There are currently three types of server configurations for which Enterprise RAs are designed: PCIe Optimized 2-4-3, PCIe Optimized 2-8-5, and HGX systems. For the PCIe Optimized configurations (for example, 2-8-5), the respective digits refer to the number of sockets (CPUs), the number of GPUs, and the number of network adapters.
The NVIDIA Enterprise RA for H200 NVL leverages a PCIe Optimized 2-8-5 reference configuration.
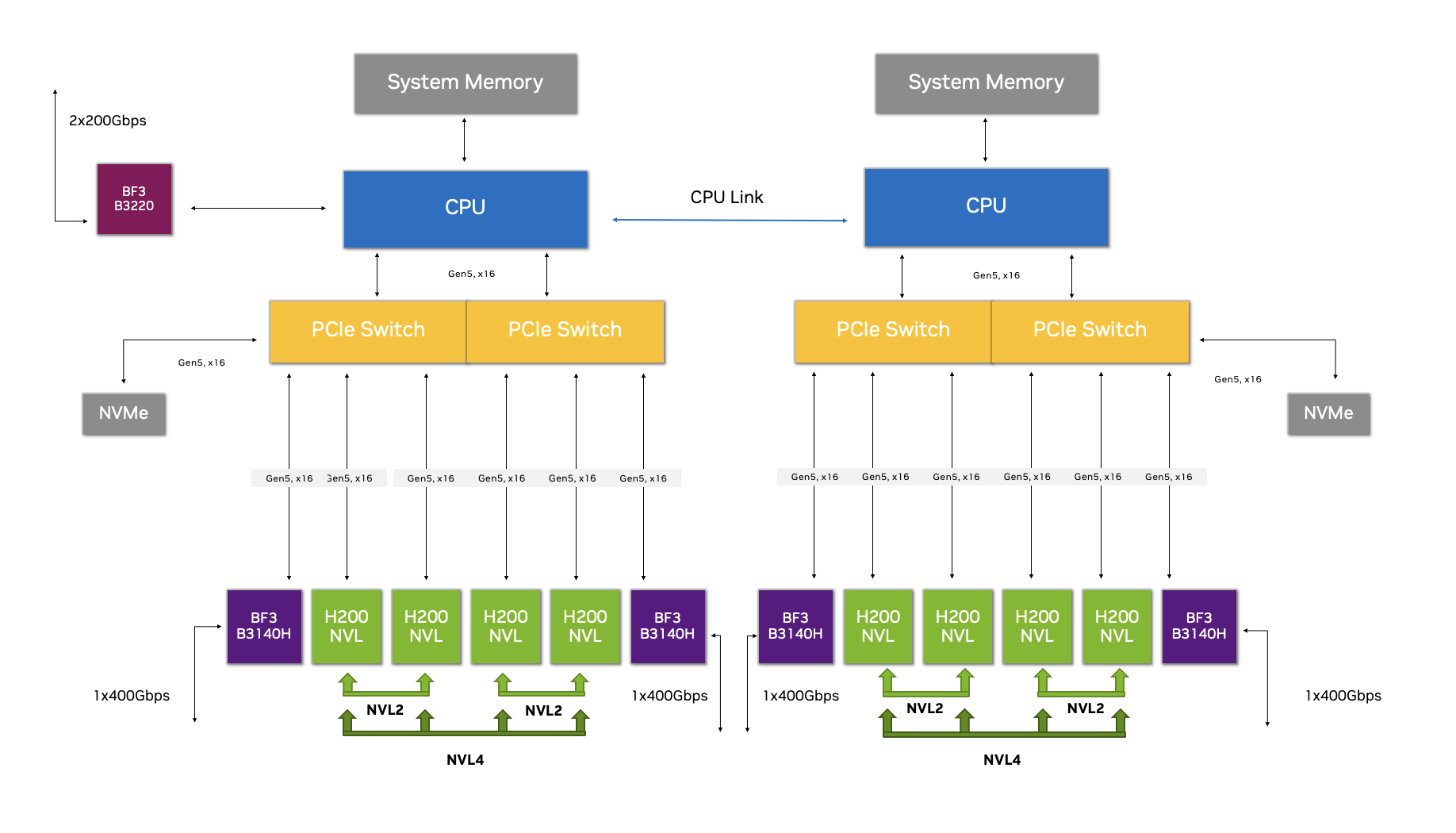
What’s unique about this configuration?
The PCIe Optimized 2-8-5 configuration with H200 NVL reduces latency, requires less CPU usage, and increases network bandwidth for real-time operations where efficient data processing is critical. It does so by enabling the creation of multiple data transfer pathways to maximize GPU-to-GPU communication.
The first data pathway is NVLink, which forms an interconnect bridge, enabling high-speed, low-latency communication between GPUs within the same memory domain. The second is with high-speed NVIDIA Spectrum-X Ethernet networking, which integrates RoCE Remote Memory Direct Access (RDMA) to provide an efficient, low-latency communication pathway between GPUs within the cluster.
A platform with unprecedented efficiency in data movement is the result of combining the H200 NVL 4-way NVLink capability with this optimized configuration. Whether through NVLink or Spectrum-X with RoCE, communications between GPUs within the server and cluster can bypass the CPU and PCIe bus—resulting in less overhead, higher throughput, and lower latency.
NVIDIA GPUDirect enables network adapters and storage drivers to read and write directly to and from GPU memory, decreasing CPU overheads. GPUDirect exists as an umbrella for GPUDirect Storage, GPUDirect Remote Direct Memory Access, GPUDirect Peer to Peer (P2P), and GPUDirect Video—all presented through a comprehensive set of APIs designed to reduce latency.
Maximizing performance of H200 NVL at scale
Now that we have covered the features of the H200 NVL and optimal server configurations, this section explores additional technologies within the NVIDIA Enterprise RA for H200 NVL that enterprises can harness to maximize performance when deploying these systems in a clustered environment.
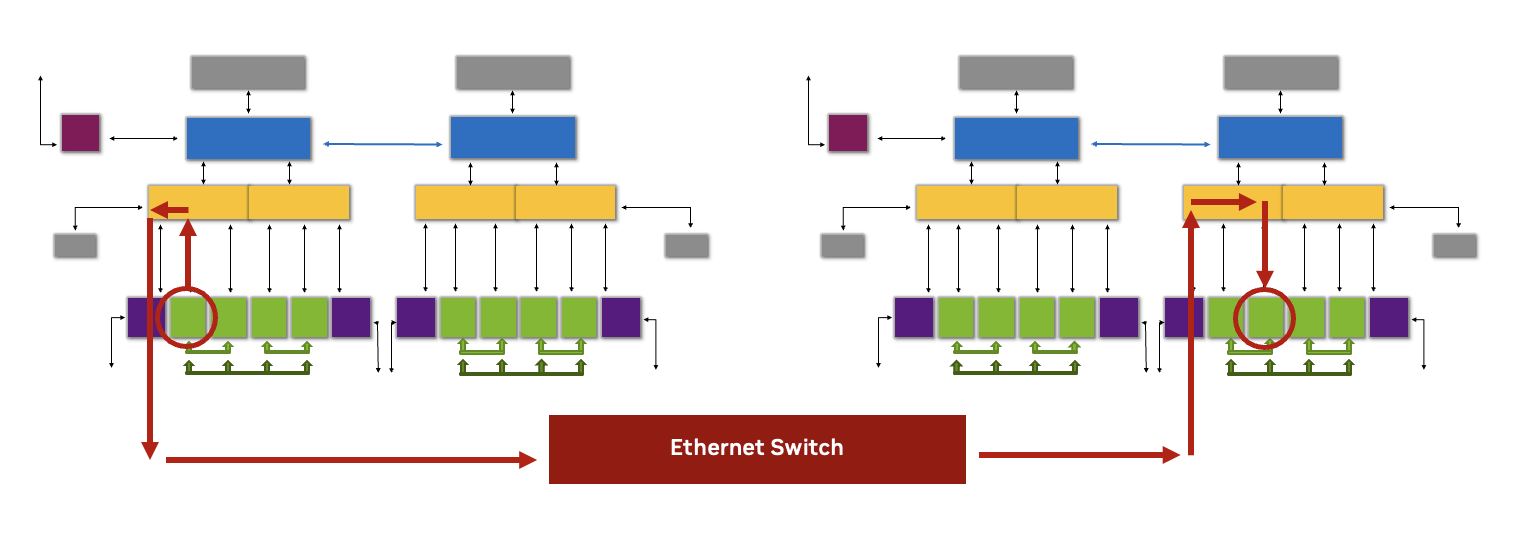
NVIDIA Spectrum-X Ethernet networking for AI
Leveraging an RDMA-based fabric provides the shortest hops through the network for applications that must communicate across cluster servers. For the compute (East-West) network fabric, the Enterprise RA for H200 NVL includes design recommendations based on the NVIDIA Spectrum-X Ethernet for AI platform, which consists of the Spectrum-4 switch and BlueField-3 SuperNIC.
To deliver peak network performance, the Enterprise RA recommends a dedicated BlueField-3 SuperNIC with a 400 gigabits per second (GB/s) connection for every two H200 NVL GPUs within the cluster. The BlueField-3 DPU within each server enables RoCE support for storage and management networks (North-South).
NVIDIA Collective Communications Library (NCCL)
The Enterprise RA for H200 NVL uses the NVIDIA Collective Communications Library (NCCL) to deliver efficient, low-latency communication and scalability for workloads that require efficient communication between multiple GPUs, such as distributed AI, deep learning, and high-performance computing (HPC).
Fully optimized for the NVIDIA accelerated computing platform, this specialized software toolkit enhances communication between multiple GPUs within a cluster, providing optimized functions that enable efficient data sharing and processing. Whether in the same server or distributed across multiple, NCCL works with the H200 NVL GPUs and NVLink technology to identify and evaluate the myriad of data communication pathways and select the optimal route.
To provide an example, agentic AI applications built with NVIDIA Blueprints will benefit significantly from NCCL optimization. These AI agents are composed of multiple NIM microservices distributed across numerous GPUs, meaning low-latency communication is critical for performance.
| Technology | Capability |
| Spectrum-X (hardware and software) | Comprehensive solution integrating both hardware and software elements to optimized AI workloads. In combination with H200 NVL, Spectrum-X provides efficient data transfer and communication through Spectrum-4 Ethernet Switches, BlueField-3 SuperNICs), and Spectrum-X Software Development Kits (SDKs), and NCCL. |
| NCCL (software) | NCCL provides optimized communication operations for the H200 NVL. NCCL is topology-aware, able to optimize underlying GPU interconnect technology like NVLink and benefits from rail-optimized topology designs where NICs are connected to specific leaf switches. The NCCL offload library is a part of NCCL and allows for offloading collective communication operations to the network, reducing the load on the CPU and improving performance. |
| NVLink Bridge (hardware) | High-speed interconnect technology, the fourth-generation of which is used in H200 NVL. Fourth-generation NVLink provides a high bandwidth of 900 GB/s for GPU-to-GPU communication, significantly higher than point-to-point interconnects. |
| Software Development Kits (SDKs) (software) | Spectrum-X SDKs work with H200 NVL and include Cumulus Linux, pure SONiC, NetQ, and NVIDIA DOCA software frameworks. These SDKs work in aggregate to ensure performance across multiple AI workloads without degradation. |
| RDMA over Converged Ethernet (RoCE) GPU Direct | Networking protocol that enables direct memory-to-memory transfers between servers and storage arrays over Ethernet networks, bypassing CPU involvement. Latency in H200 NVL inter-system communication is reduced by RoCE while NVLink reduces response time for intra-system GPU communication. |
Build with NVIDIA H200 NVL
With high-performance and enhanced capabilities, this latest edition to the NVIDIA Hopper family significantly advances enterprise-grade AI and HPC acceleration. Enterprises ready to transform their data center infrastructure can explore next-generation platforms in various configurations featuring H200 NVL through the NVIDIA global systems partner ecosystem.
The NVIDIA Enterprise RA for H200 NVL is now available for partners building high-performance, scalable data center solutions. This Enterprise RA reduces complexity when designing and deploying data center infrastructure by providing proven and comprehensive design recommendations for deploying H200 NVL at scale.
Learn more about NVIDIA Enterprise Reference Architectures.