

{kind=link}
Large language models (LLMs) are rapidly changing the business landscape, offering new capabilities in natural language processing (NLP), content generation, and data analysis. These AI-powered tools have improved how companies operate, from streamlining customer service to enhancing decision-making processes.
However, despite their impressive general knowledge, LLMs often struggle with accuracy, up-to-date information, and domain-specific knowledge. This can lead to potential misinformation and oversimplification in specialized fields like architecture, construction, and engineering (AEC), where precise and current information is critical for making informed decisions and ensuring compliance with industry regulations.
Consider a design team consisting of an architect and an engineer using an LLM to come up with ideas for a house in a mountain area. When asked about incorporating sustainable building techniques suitable for the local climate, the LLM might provide a generic response about using solar panels and green roofs, without considering the specific challenges of high-altitude environments such as extreme temperature fluctuations and potential snow loads. In a more problematic scenario, the LLM could hallucinate and suggest the use of “solar snow-melt panels”—a technology that sounds innovative but doesn’t exist.
This example shows a common problem with LLMs. They have a lot of knowledge, but they often don’t have the current information needed for specific tasks. This limitation stems from several inherent challenges. Specifically, LLMs are trained on data available up to a specific cutoff date and do not have access to proprietary or real-time business data. LLMs can sometimes also misinterpret the context or intent behind a query, which can lead to irrelevant or ambiguous responses.
To address these limitations, companies typically have three options:
- Retrain the entire model: This involves completely retraining the LLM on a dataset that includes domain-specific information. However, this process is extremely resource-intensive, requiring vast amounts of data, significant computational power, and substantial time investment, making it impractical for most organizations.
- Fine-tune the model: This approach adapts a pretrained model to a specific domain by training it further on a smaller, specialized dataset. While less intensive than full retraining, fine-tuning still requires considerable computational resources and expertise. It can be effective but may still struggle with very specific or rapidly changing information.
- Use retrieval-augmented generation (RAG): An efficient and flexible solution to the limitations of LLMs, RAG combines the broad capabilities of LLMs with the ability to retrieve and incorporate specific, up-to-date information from a curated knowledge base. This approach enables companies to leverage the power of LLMs while ensuring accuracy and relevance in domain-specific applications.
RAG offers a clear way forward for businesses who want to use advanced language models while reducing their risks and limitations.
This post explores why RAG represents a transformative advancement for the AEC industry and why leading organizations are choosing to develop RAG systems to enhance value for their businesses.
What is retrieval-augmented generation?
RAG is an advanced AI technique that combines the capabilities of language models with real-time information retrieval, enabling systems to access and use specific, contextually relevant data from defined sources to improve the accuracy and relevance of generated responses. It is a powerful approach for enhancing AI capabilities in the enterprise sector.
For LLMs to truly solve business problems, they need to be attuned to the unique body of knowledge that each organization possesses. RAG enables AI systems to access and retrieve real-time information from defined sources, like in-house company knowledge systems, datastores, and even other SaaS applications like CRMs and ERPs, before generating responses.
This means that when an employee asks a question or seeks information, for example, the AI assistant using RAG understands the context: the firm’s historical project data, current project details, supply chain information, and other proprietary organizational knowledge to provide a tailored, accurate response.
Consider the AECOM BidAI initiative that leverages LLMs and RAG to enhance their bid writing process. A general knowledge-trained LLM might broadly explain bid writing strategies, but this would be insufficient for AECOM’s specific needs in crafting complex, tailored plans for large construction projects.

This is where RAG becomes crucial. It enables AI systems like BidAI to access and retrieve real-time information from defined sources, including AECOM’s vast repository of over 30,000 indexed artifacts such as past proposals, project data sheets, and resumes. When an AECOM employee needs to draft a bid, the AI assistant using RAG understands the context: the firm’s historical project data, current project details, and other proprietary organizational knowledge.
With this, the system can provide tailored, accurate, and grounded assistance, significantly reducing bid drafting time from 10 days to just 2 days. By combining GPT foundation models with RAG vector search, AECOM has created a powerful knowledge platform that democratizes organizational expertise and dramatically improves efficiency in bid writing and other areas of their business.
By bridging the gap between vast, general-purpose AI models and specific, up-to-date organizational knowledge, RAG is positioning itself as a crucial enabler for the practical, real-world application of LLMs in business environments.
Harnessing RAG in the AEC industry
Integrating RAG with operational data can significantly enhance the potential of generative AI, enabling the delivery of real-time, highly personalized, and contextually relevant experiences throughout enterprise applications.
RAG-based LLM solutions are transforming the AEC industry by providing intelligent workplace assistants that can be used for design document retrieval, compliance checking, project management, cost estimation, knowledge management, and customer support. These RAG-based AI tools offer significant benefits:
- Improved accuracy: Reduce errors and hallucinations by grounding responses in current, industry-specific information, allowing architects and engineers to efficiently access essential project specifications.
- Specialized knowledge access: Use your own data in a safe place to give you personalized answers that match company practices and rules. Analyze past projects for customized design recommendations and actionable insights, all while protecting sensitive information and ensuring access is restricted to authorized users.
- Regulatory compliance: Ensure compliance with various standards, including building codes for municipalities, industry safety guidelines, and environmental regulations, and generate customized client proposals to keep firms competitive.
- Traceability and efficiency: Users can trace AI-generated content back to its source, enhancing trust and accountability. By focusing on relevant data, RAG reduces the need for extensive model retraining, saving time and resources.
Core components of RAG
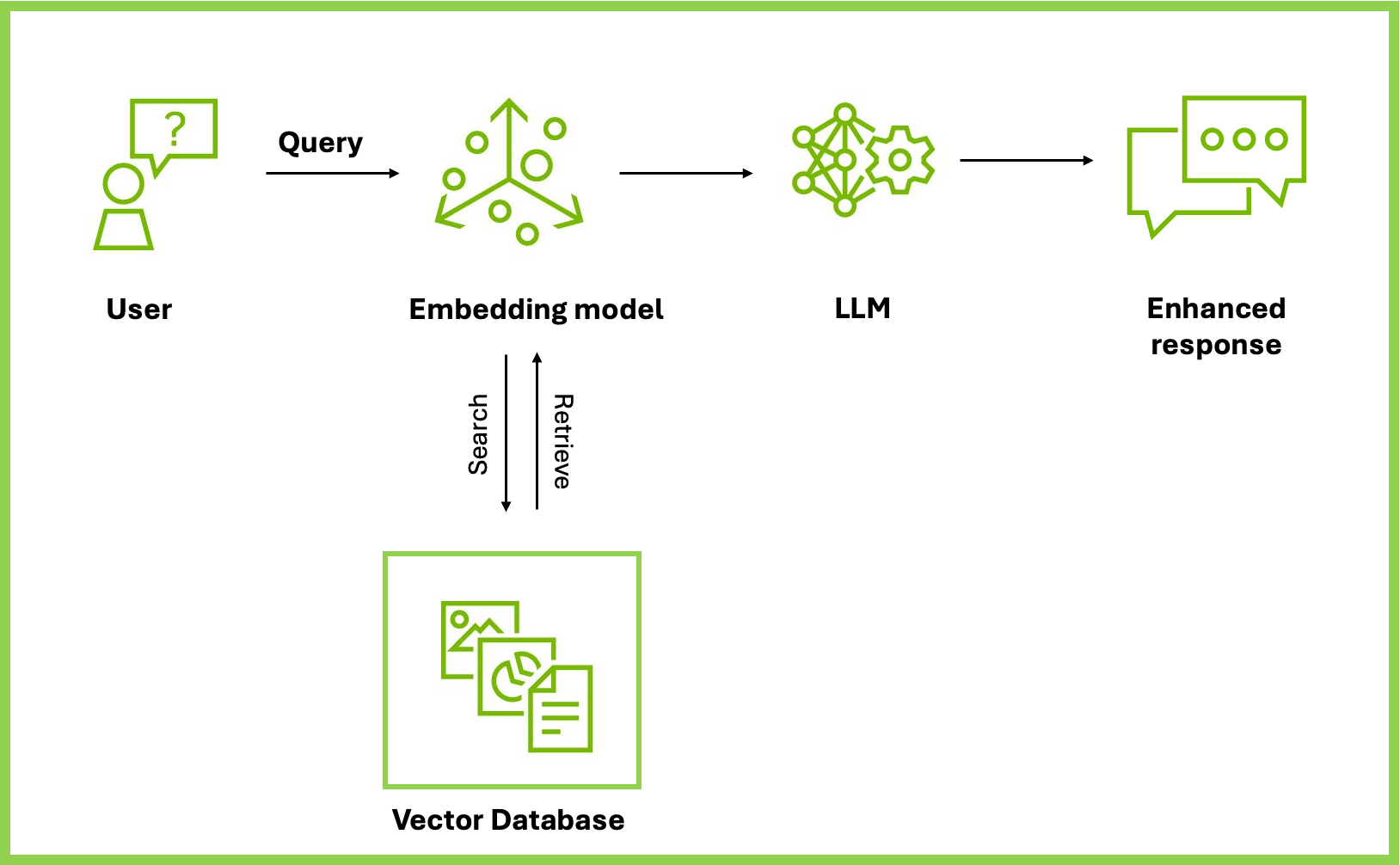
Implementing RAG requires careful consideration of data management, model selection, and integration with existing workflows. The workflow consists of several key components that work together to enhance the capabilities of LLMs. These components can be broadly categorized into data ingestion, data retrieval, data generation, and continuous improvement processes.
Data ingestion
The first stage is data ingestion, where raw data from various sources such as databases, documents, or cloud storage is collected and prepared for processing. This step is crucial for ensuring that the system has access to comprehensive and relevant information. RAPIDS can accelerate this phase by providing GPU-accelerated data preprocessing capabilities, ensuring that large volumes of data are ingested efficiently.
Embedding generation
Next is the embedding generation phase, where the ingested data is converted into vector embeddings that capture the semantic meaning of the text. Here an embedding model works like a translator, converting chunks of text from project documents, building codes, or design specifications into a special format called “vector embeddings.” These embeddings capture the meaning and context of the text, not just the exact words.
For example, an embedding model could understand that “steel beam” and “I-beam” are related concepts, even if they don’t share the same words. NVIDIA NeMo Retriever, a collection of microservices for information retrieval, offers powerful embedding models specifically designed for tasks like question-answering and information retrieval. These embeddings are crucial for enabling accurate and context-aware information retrieval.

Storing and retrieving embeddings
The third stage involves storing and retrieving these embeddings using a vector database – think of this as a smart knowledge base.
Response generation
Finally, the response generation phase involves using an LLM to generate answers based on the information retrieved from the vector database. NVIDIA GPUs accelerate the inference process of LLMs, enabling faster, efficient, and real-time response generation. To further optimize performance, NVIDIA Triton Inference Server manages the deployment of these models, ensuring they run at peak efficiency. Triton handles inference requests and model settings in a way that reduces latency and maximizes resource use. This makes it ideal for real-time AI applications.
Example use case
To understand these concepts, consider an architect who needs to ensure compliance with local building codes related to fire safety. The architect inquires about the fire safety requirements for high-rise building. In the first step of the RAG workflow, the architect’s question is processed by an embedding model. This model converts the question into a vector embedding, capturing its semantic meaning. The model understands that the question relates to fire safety requirements and high-rise buildings.
Next, the question’s vector embedding is used to search the vector database that contains embeddings of various documents, including local building codes, design guidelines, and past project documents. NVIDIA RTX GPUs play a crucial role in accelerating this search process, allowing the system to quickly find the most relevant documents related to fire safety and high-rise buildings.
Once the relevant documents are retrieved, the system extracts key information about fire safety requirements. This might include specific regulations, compliance checklists, and examples of past projects that adhered to these standards. The system then moves to the response generation phase, where the LLM synthesizes the retrieved information to create a comprehensive answer to the architect’s query, including any specific codes or standards that must be followed.
Build your own RAG pipelines
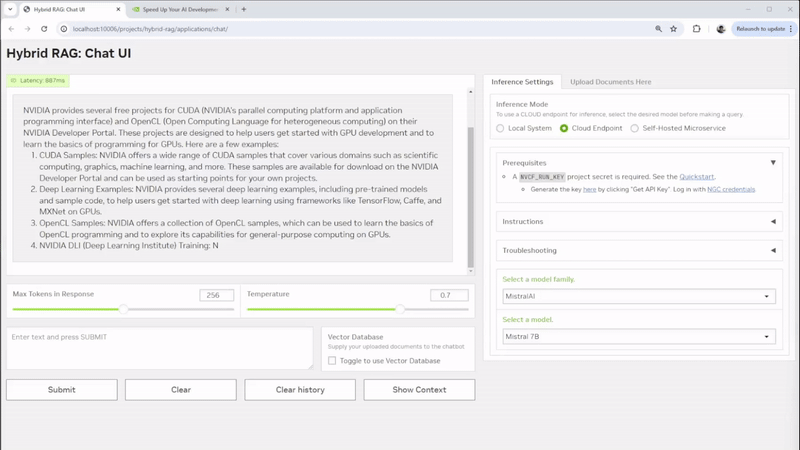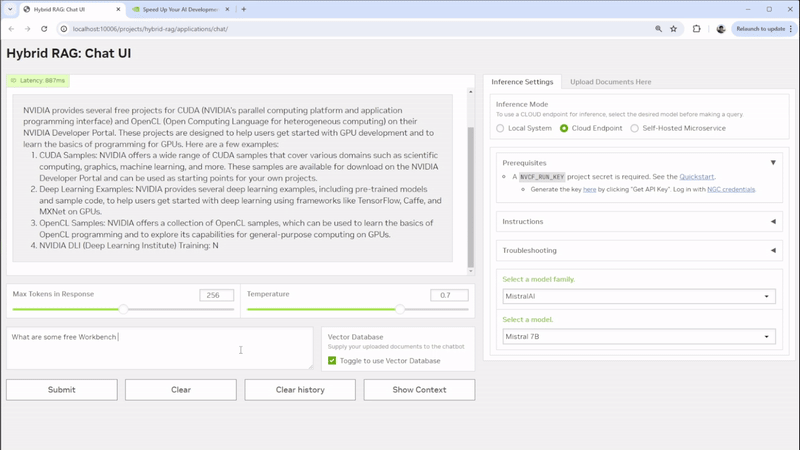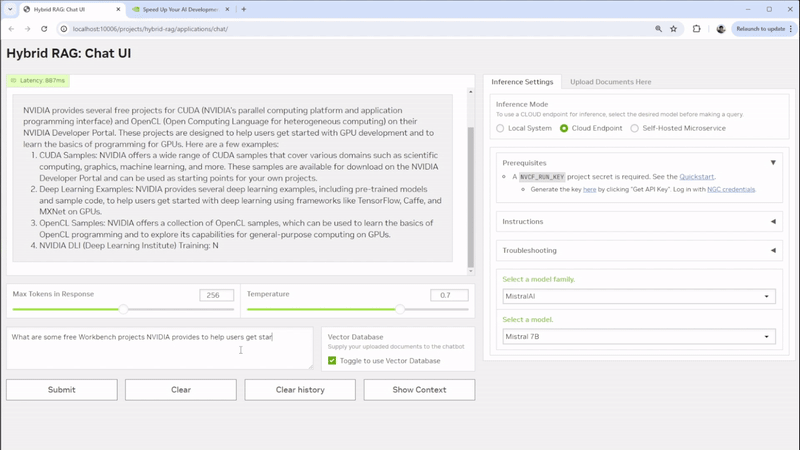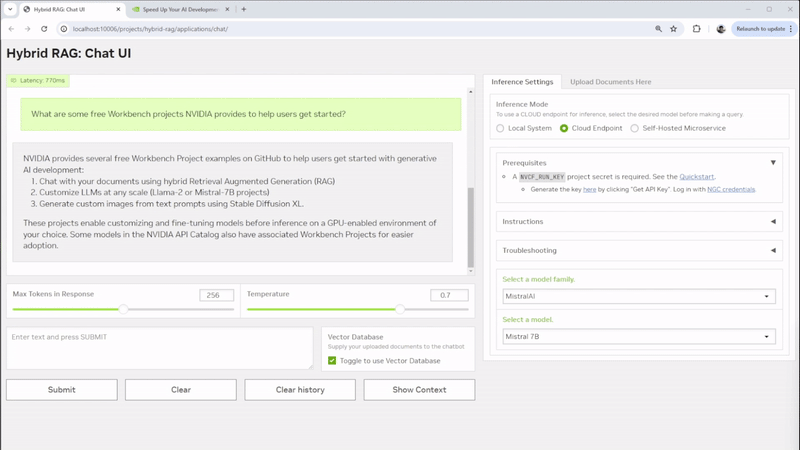
AEC firms can get started with RAG using NVIDIA ChatRTX. This demo app serves as a low-effort experimental tool for individual users to personalize a GPT LLM with their own content—such as documents, notes, and images—to create context-aware, locally run chatbots or virtual assistants. Users can quickly retrieve information on design precedents, building code requirements, and project updates, all while ensuring sensitive information remains secure on local RTX PCs or workstations.
For developers and data scientists seeking more control and customization, NVIDIA AI Workbench offers a robust environment for creating, customizing, and collaborating on sophisticated AI applications such as the AI Workbench Hybrid RAG project. Developers can chat with a variety of their documents ranging from design documents, to project specifications, creating a cohesive system that enhances information retrieval and decision-making. The flexibility of this platform allows for deployment across various environments, whether on local workstations, servers or in the cloud, ensuring that the solution can scale and adapt to the infrastructure available.
While AI Workbench provides a comprehensive development environment, NVIDIA has also introduced NVIDIA NIM to streamline the deployment of AI models. NIM microservices package optimized inference engines, industry-standard APIs, and support for AI models into containers for easy deployment. NIMs are particularly beneficial for RAG deployments, as they integrate NVIDIA NeMo Retriever microservices, which optimize data retrieval for RAG applications.
NVIDIA AI Blueprints provide a jump-start for developers creating AI applications that use one or more AI agents. These pretrained, customizable AI workflows accelerate the development and deployment of generative AI applications across various use cases.
They include sample applications built with NVIDIA NeMo, NVIDIA NIM and partner microservices, reference code, customization documentation and a Helm chart for deployment.

For AEC firms, the NVIDIA AI Blueprint for multimodal PDF data extraction is particularly valuable, as it leverages NVIDIA NeMo Retriever NIM microservices to process complex PDF documents containing both text and images. This blueprint enables AEC firms to harness their vast repositories of internal design and specification data, allowing teams to access and utilize this information more intelligently and rapidly than ever before. AI Blueprints are free for developers to experience and download and can be deployed in production with the NVIDIA AI Enterprise software platform.
Conclusion
As the AEC industry continues to digitize and embrace AI technologies, RAG stands out as one of the easiest ways to get started with AI. This practical approach enables companies to harness the power of generative AI while maintaining the accuracy and relevance crucial in this field. AECOM recognizes the profound impact that generative AI and RAG-based solutions will have on the future of work, and their commitment to this technology is evident in their ongoing initiatives aimed at democratizing knowledge and enhancing client service.
“Generative AI will no doubt accelerate changes in the way we work and continue to improve how we deliver value to our clients,” said Tim Wark, global AI lead at AECOM. “Our early initiatives around RAG and LLMs have shown enormous potential around the value of democratizing our global knowledge base and building on that to provide deeper insights to our clients. These are the beginnings of exciting times of change for our whole industry.”
By bridging the gap between vast language models and specific industry knowledge, RAG is poised to transform how AEC professionals interact with and use AI in their daily operations. This transformation is part of a broader trend in the industry, where 80.5% of AEC professionals plan to use digital tools, including AI, reflecting a readiness to embrace digital transformation and the benefits it brings.
Learn more about how AI is transforming the AEC industry.