
{kind=link}
Generative AI has evolved from text-based models to multimodal models, with a recent expansion into video, opening up new potential uses across various industries. Video models can create new experiences for users or simulate scenarios for training autonomous agents at scale. They are helping revolutionize various industries including robotics, autonomous vehicles, and entertainment.
The development of video foundation models presents unique challenges due to the vast and varied nature of video data. This also underscores the necessity of scalable pipelines for curating data and effectively training models that can comprehend temporal and spatial dynamics.
We are announcing brand new video foundation model capabilities in the NVIDIA NeMo framework, an end-to-end training framework that enables you to pretrain and fine-tune your own video foundation models. The framework includes a high-throughput data curation, efficient multimodal data loading functionality, scalable model training, and a parallelized in-framework inference.
High-throughput video curation through optimized pipelines
NeMo Curator improves generative AI model accuracy by efficiently processing and preparing high-quality data, including large video datasets.
Using NeMo Curator’s scalable data pipelines, you can efficiently clip, annotate, and filter 100 PB or more of videos. To remove bottlenecks and optimize performance, NeMo Curator uses the following combination:
- NVDEC: Hardware decoder
- NVENC: Hardware encoder
- Ray: Compute framework for scaling AI applications
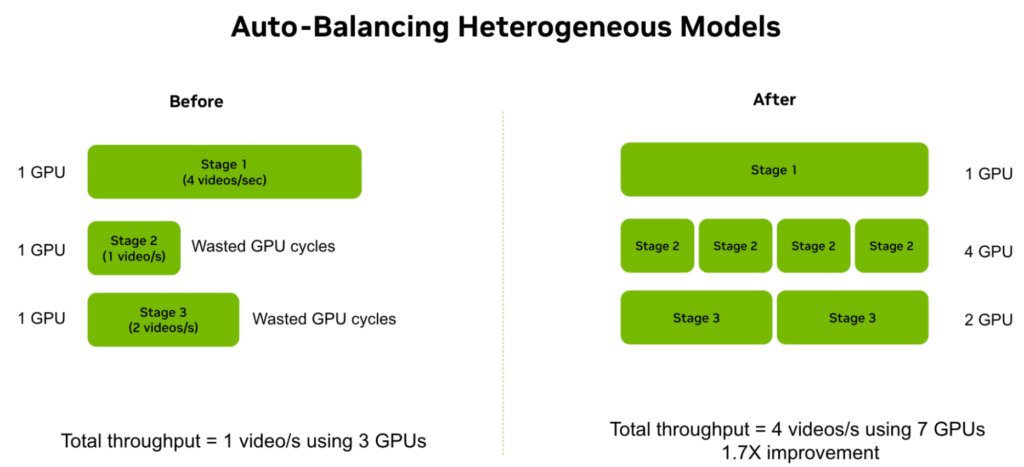
The NeMo Curator autobalancing techniques can leverage heterogeneous clusters with multiple GPU types to take advantage of NVENC on L40S GPUs and the performance of H100 and GB200 GPUs.
Figure 1 shows how NeMo Curator can process 20M hours of video data, reducing the processing time from years to days, achieving 89x speed up using 1K GPUs compared to unoptimized pipelines on CPUs for ISO power usage.

NeMo Curator provides the following relevant pipelines for video foundation model training and fine-tuning datasets:
The clipping pipeline starts with decoding and splitting raw videos into short, continuous clips by analyzing frame-to-frame color changes. The stitching stage smooths the clips out by using image embedding similarities to potentially merge adjacent clips together. These clips are then transcoded to the high-quality video encoding (H264), and they are annotated with video embeddings and captions, either existing or synthetically generated by a VLM, to facilitate semantic search capabilities.
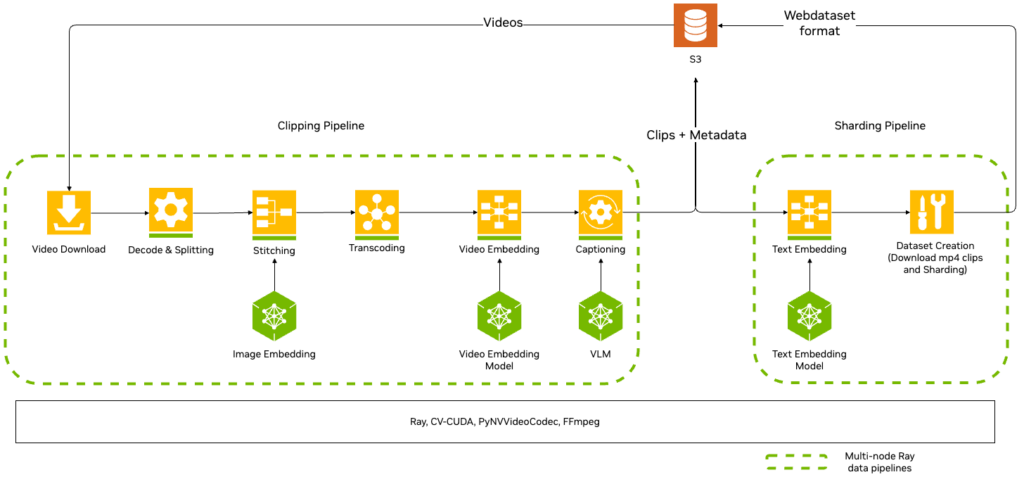
Sharding generates text embeddings for captions to create the final WebDataset used for training. NeMo Curator also uses Ray streaming to build an auto-balancing system and deploy an optimal number of workers for each stage in the pipeline to avoid being bottlenecked by any stage (Figure 3).
Efficient multimodal dataloading
Video models can be trained on billions of images and millions of videos, necessitating an efficient data loading strategy to achieve high throughput during training time.
This is accomplished in the NeMo framework through the use of Megatron-Energon data loader:
- Shard large-scale data: Uses the WebDataset format to shard a TB-size dataset into compressed files to help reduce I/O overhead during training.
- Deterministic save and load: Enables the dataset to be visited in one pass without repetition when the training job is disrupted, ensuring consistency across different training cluster setups.
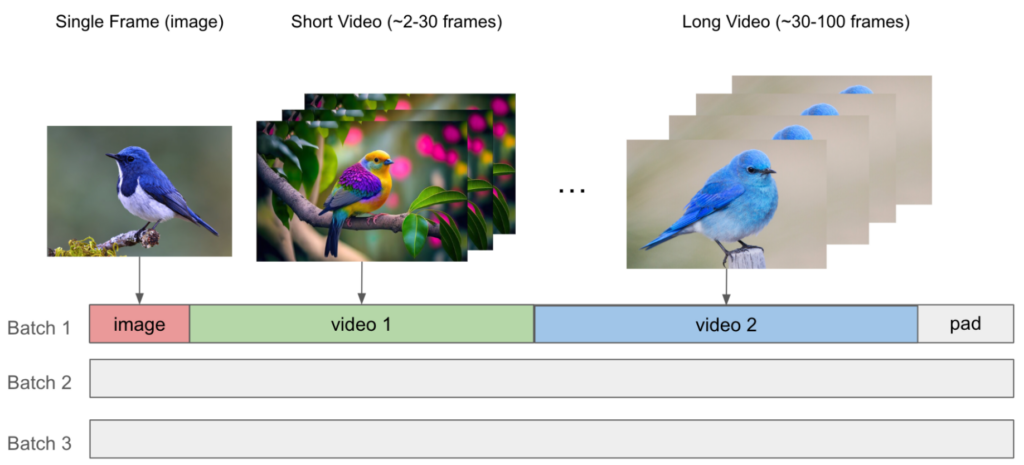
- Sequence packing: Packs variable length or resolution images and videos together up to the max sequence length, minimizing compute wastage due to padding while simplifying data loading logic. NeMo uses the special THD attention kernel from the Transformer engine to support accelerated training with sequence packing.
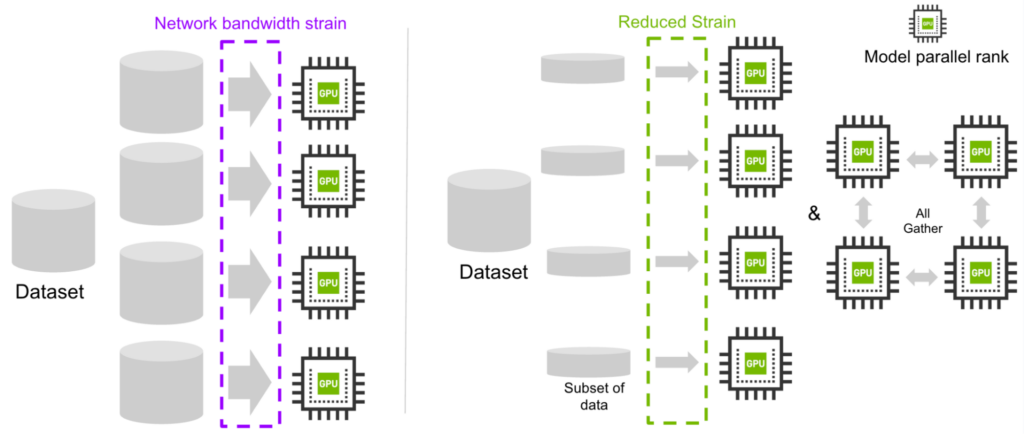
- Reduce network bandwidth strain: Each model parallel rank downloads a different subset of data instead of the whole dataset, and then all-gathers the data across ranks to get an identical dataloader.
Scaling video foundation model training
Video foundation models can be either autoregressive or diffusion models.
The well-established suite of NeMo tools on large language models (LLMs) can be reused for autoregressive models, while support for diffusion transformers such as DiT, MovieGen, and the latest NVIDIA Cosmos world foundation models for physical AI have been newly added.
The NeMo tech stack is highly optimized and provides more than 40% Model FLOPs utilization (MFU) in the latest benchmark (Table 1).
| Model size | Context length | Training config | GPU used (TFLOPS/s) | Throughput (token/s/GPU) |
| DiT 7B | 8k | baseline, no optimization | OOM | |
| DiT 7B | 8k | CP=2 | 457 | 8,969 |
| DiT 7B | 74k | TP=4 SP CP=4 | 414 | 2,933 |
| DiT 28B | 8k | TP=2 SP PP=2 | 435 | 2,392 |
| DiT 28B | 74k | TP=8 SP CP=4 PP=4 | 411 | 994 |
Legend: CP=context parallelism; TP=tensor parallelism; SP=sequence parallelism; PP=pipeline parallelism
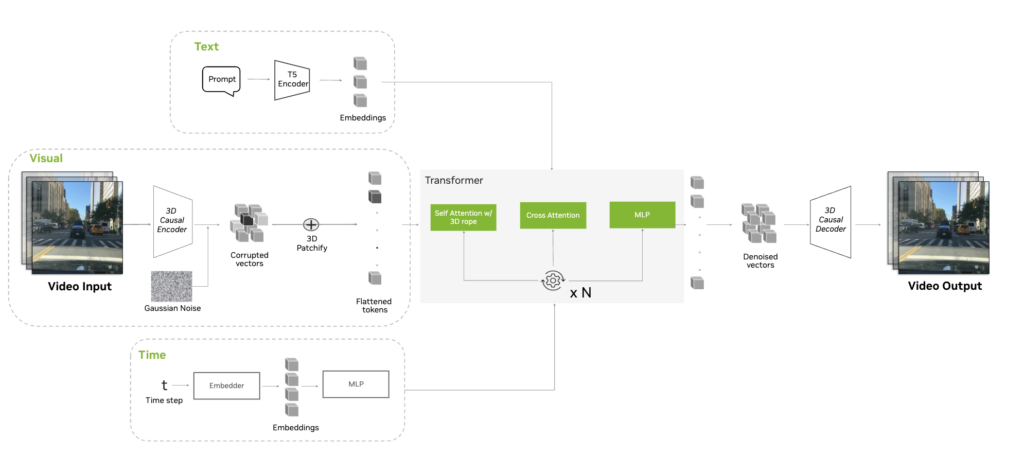
Overview of the video diffusion pipeline
A video diffusion training pipeline is generally composed of the following major steps:
- Tokenize the input image and video with a causal temporal 3D tokenizer to generate 3D spatio-temporal tokens.
- Use a transformer decoder conditioned by the diffusion noise schedule timestep t and text input.
- Timestep conditioning is applied through an Adaptive LayerNormalization (AdaLN) mechanism, with an option to use AdaLN-LoRA, which further improves Model FLOPs Utilization (MFU) during training.
- Text conditioning is applied through a cross attention layer in each transformer block.
- The NeMo framework enables you to initialize your transformer decoder based on the canonical DiT architecture or the MovieGen Llama architecture, which uses Grouped-Query Attention (GQA).
- Compute the diffusion loss with the parallelized EDM diffusion pipeline using the noise prediction from the diffusion transformer.
NeMo also applies additional Root Mean Square Layer Normalization (RMSNorm) on the queries and keys before attention blocks to stabilize diffusion training. RMSNorm is applied per attention head to remain compatible with tensor parallelism.
Parallelism optimizations for video diffusion models
NeMo and Megatron-Core enable various model parallelism techniques:
- Tensor parallel (TP)
- Sequence parallel (SP)
- Pipeline parallel (PP)
- Context parallel (CP)
However, these techniques face unique challenges when applied to video diffusion transformers. Here’s how NeMo solves these challenges to achieve scalable and performant training:
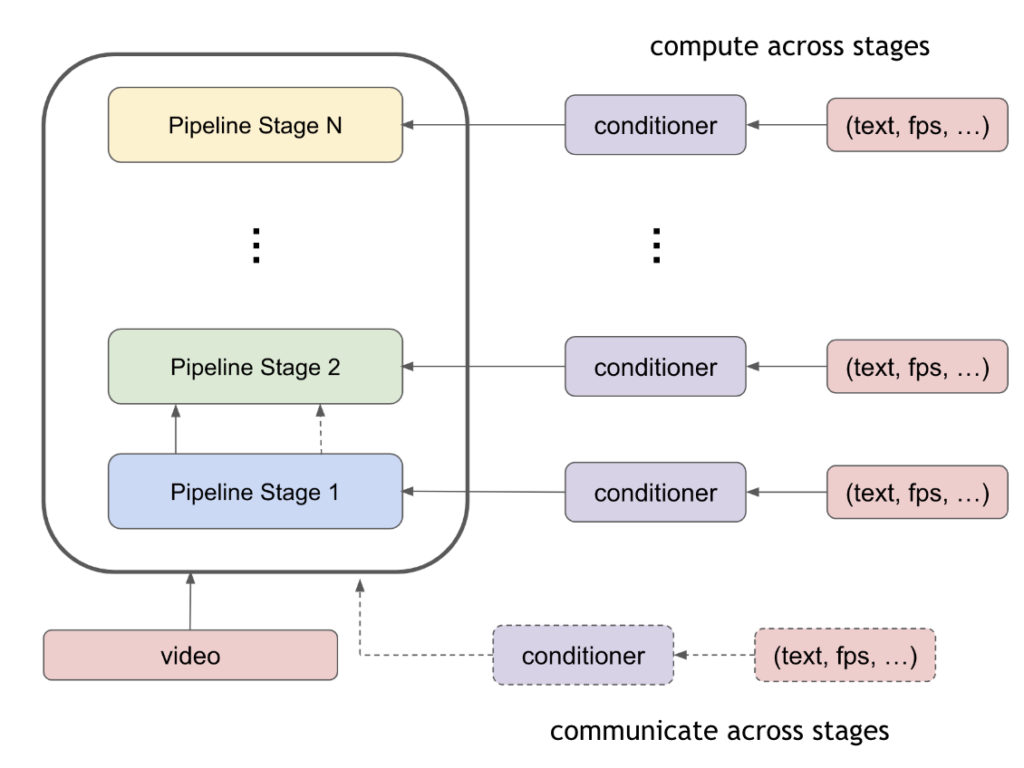
- Efficient pipeline parallelism for conditioning
- Support for Spatio-Temporal DiT (ST-DiT) architecture
- Customized random seeding mechanism
The traditional approach is to communicate conditioning information across pipeline stages, incurring additional communication cost and requiring nontrivial modifications to the pipeline schedule. NeMo solves this problem by computing the conditional embeddings at each pipeline stage. The computation cost with efficient pipeline parallelism for conditioning is much less than the communication cost and improves training throughput.
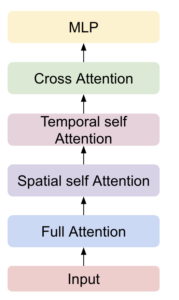
The Spatio-Temporal DiT (ST-DiT) architecture introduces additional spatial and temporal self-attention layers to each transformer block, as an alternative to training with full self attention on long video sequences. This approach exposes communication overhead during context parallelism due to smaller compute over short input sequence for these layers. NeMo addresses this by using local attention computation with A2A communication for spatial/temporal attention, while maintaining P2P ring topology for full self-attention. The hybrid approach effectively reduces bandwidth needs for temporal/spatial attention while still benefiting from context parallelism over full self-attention layer (Table 2).
| Layer | Input Seq | Communication primitive | Communication bandwidth |
| Temporal self-attention | Short seq | Local compute & A2A | (bhw/cp, t, d) |
| Spatial self-attention | Short seq | Local compute & A2A | (bt/cp, hw, d) |
| Full attention | Long seq | CP with P2P | (b, h*w*t/cp, d) |
Legend: b=batch size; h*w=spatial size; t=temporal size; cp=context parallel size; d=hidden size, with input size being (b, t*h*w, d).
The customized random seeding mechanism goal is to make sure that random seeds are correctly initialized across the following components:
- Time step
- Gaussian noise
- The actual model weights
Table 3 shows NeMo’s initialization strategy.
| RNG seed | Data parallel | Context parallel | Pipeline parallel | Tensor parallel |
| Time step (t) | Diff | Same | Same | Same |
| Gaussian noise | Diff | Diff | Same | Same |
| Weight initialization | Same | Same | Diff | Diff |
Legend: Diff=Different random seed from other parallel ranks; Same=Same random seed as other parallel ranks.
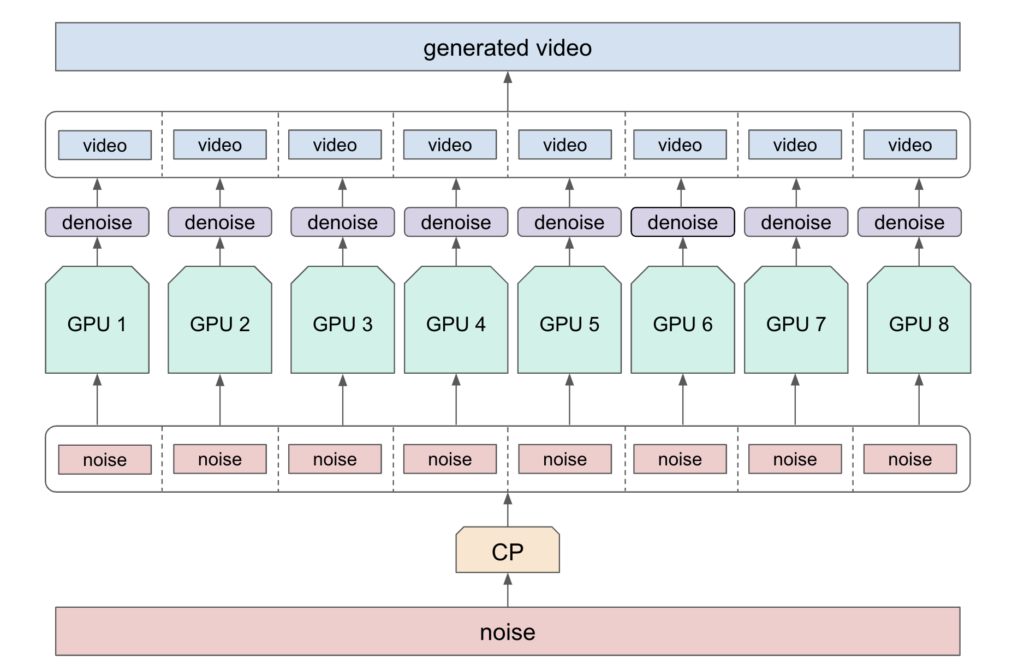
Efficient in-framework inference
The NeMo framework accelerates inference by distributing denoising operations across multiple GPUs through context parallelism. After parallel denoising, the latent tensors are combined to reconstruct the video sequence before decoding with the Cosmos video tokenizer.
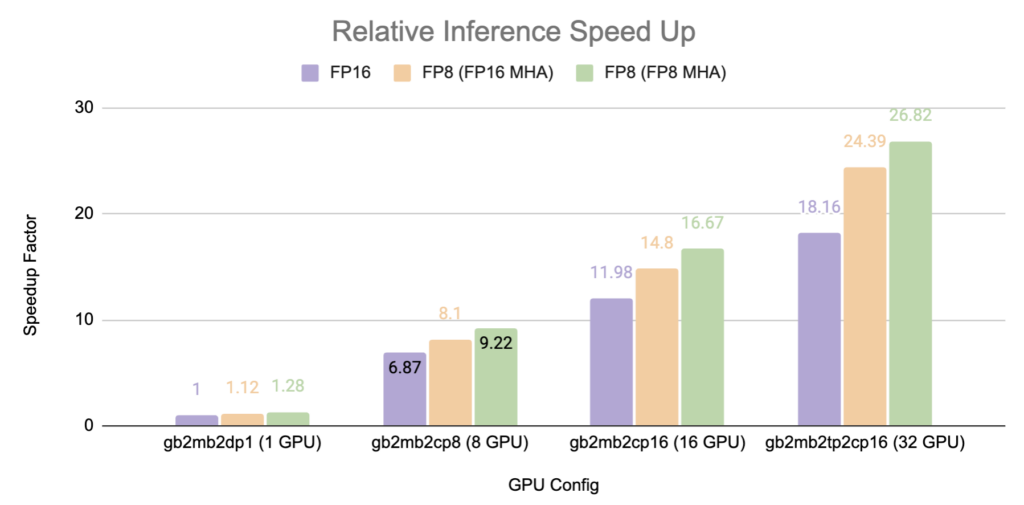
Benchmarks show 80–90% scaling efficiency on up to 32 H100 GPUs, with FP8 Multi-Head Attention providing 28% and 48% performance improvements over BF16 on 1 and 32 GPUs respectively.
Conclusion
In this post, we covered all the features of NVIDIA NeMo framework that will help you pretrain or fine-tune video foundation models in an effective and efficient manner.
NeMo Curator offers high-throughput data curation through clipping and sharding pipelines, and the Megatron Energon library offers efficient multimodal data loading. NeMo Frameworks enables scalable video foundation model training by supporting various model parallelism techniques specially optimized on diffusion and autoregressive models. In addition, it provides efficient in-framework inference by distributing denoising operations across multiple GPUs and incorporating FP8 Multi-Head Attention.
You can curate your video data with NeMo Curator early access program, tokenize them, pre-train(diffusion, autoregressive), fine-tune (diffusion, autoregressive), and perform multi-GPU in-framework inference (diffusion, autoregressive)with NeMo Framework today.
You can also try the NVIDIA Cosmos world foundation models at build.nvidia.com and watch the CES keynote from NVIDIA CEO Jensen Huang to learn more about the NVIDIA Cosmos world foundation model platform.
Acknowledgements
Thanks to the following contributors: Parth Mannan, Xiaowei Ren, Zhuoyao Wang, Carl Wang, Jack Chang, Sahil Jain, Shanmugam Ramasamy, Joseph Jennings, Ekaterina Sirazitdinova, Oleg Sudakov, Linnan Wang, Mingyuan Ma, Bobby Chen, Forrest Lin, Hao Wang, Vasanth Rao Naik Sabavat, Sriharsha Niverty, Rong Ou, Pallab Bhattacharya, David Page, Jacob Huffman, Tommy Huang, Nima Tajbakhsh, and Ashwath Aithal.