The NVIDIA Nemotron family builds on the strongest open models in the ecosystem by enhancing them with greater accuracy, efficiency, and transparency using NVIDIA open synthetic datasets, advanced techniques, and tools.
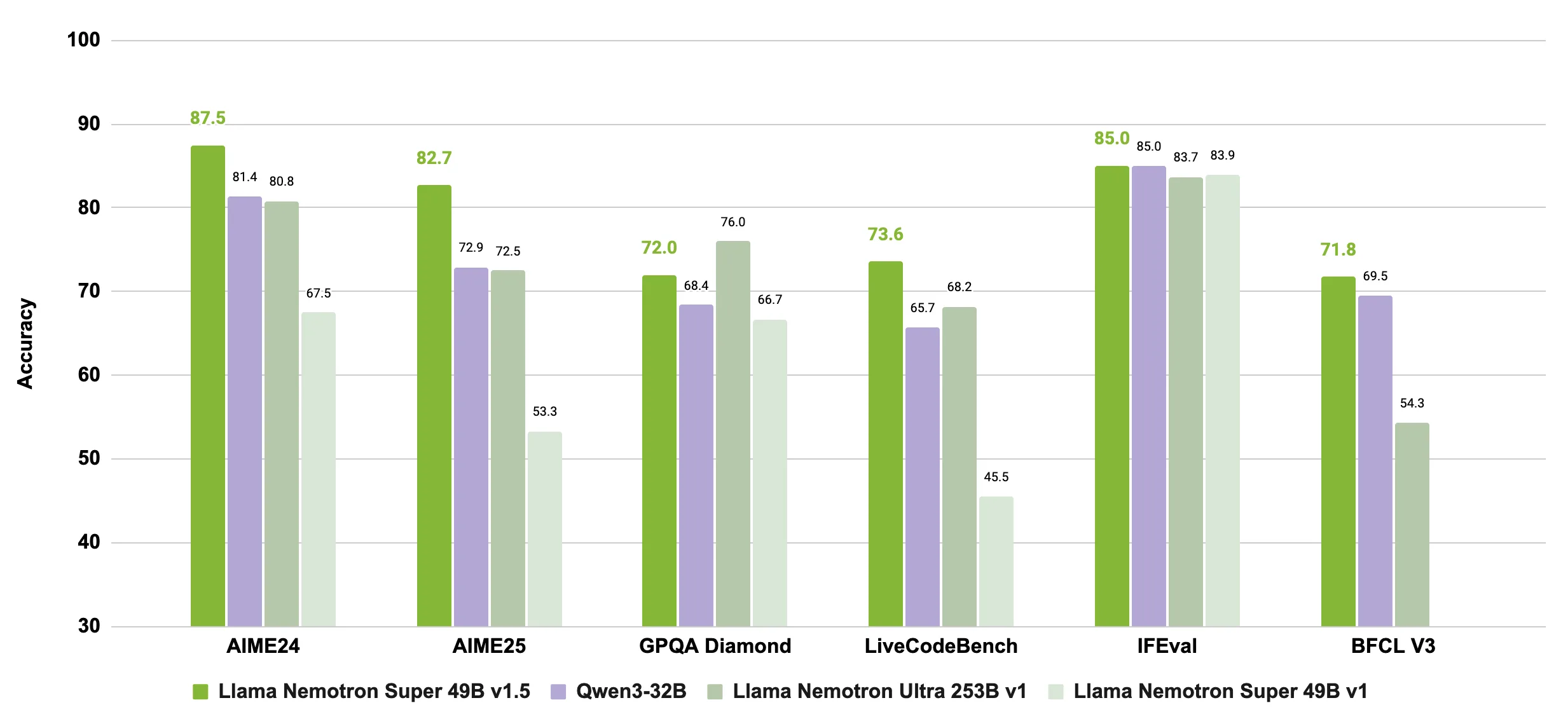
Today, we’re introducing NVIDIA Llama Nemotron Super v1.5, which brings significant improvements across core reasoning and agentic tasks like math, science, coding, function calling, instruction following, and chat, while maintaining strong throughput and compute efficiency.
Built for reasoning and agentic workloads
Llama Nemotron Super v1.5 builds on the same efficient reasoning foundation as Llama Nemotron Ultra. However, the model has been refined through post-training using a new dataset focused specifically on high-signal reasoning tasks.
Across a wide range of benchmarks, Llama Nemotron Super v1.5 outperforms other open models in its weight class, particularly in tasks that require multi-step reasoning and structured tool use.

To boost throughput and deployment efficiency, we applied pruning techniques like neural architecture search. Higher throughput means the model can reason faster and explore more complex problem spaces within the same compute and time budget—delivering stronger reasoning at lower inference costs. It also runs on a single GPU, further reducing compute overhead.

Try the model now
Experience Llama Nemotron Super v1.5 now at build.nvidia.com, or download the model directly from Hugging Face.