NVIDIA TensorRT is an AI inference library built to optimize machine learning models for deployment on NVIDIA GPUs. TensorRT targets dedicated hardware in modern architectures, such as NVIDIA Blackwell Tensor Cores, to accelerate common operations found in advanced machine learning models. It can also modify AI models to run more efficiently on specific hardware by using optimization techniques such as layer fusion and automatic kernel tactic selection.
Popular frameworks such as PyTorch provide an intuitive and consistent interface for working with AI models; however, they can’t always achieve peak performance. Torch-TensorRT bridges this gap. It’s a powerful compiler for PyTorch models, delivering TensorRT-level performance on NVIDIA GPUs, while maintaining PyTorch class usability. It enables you to double performance over native PyTorch without requiring changes to PyTorch APIs.
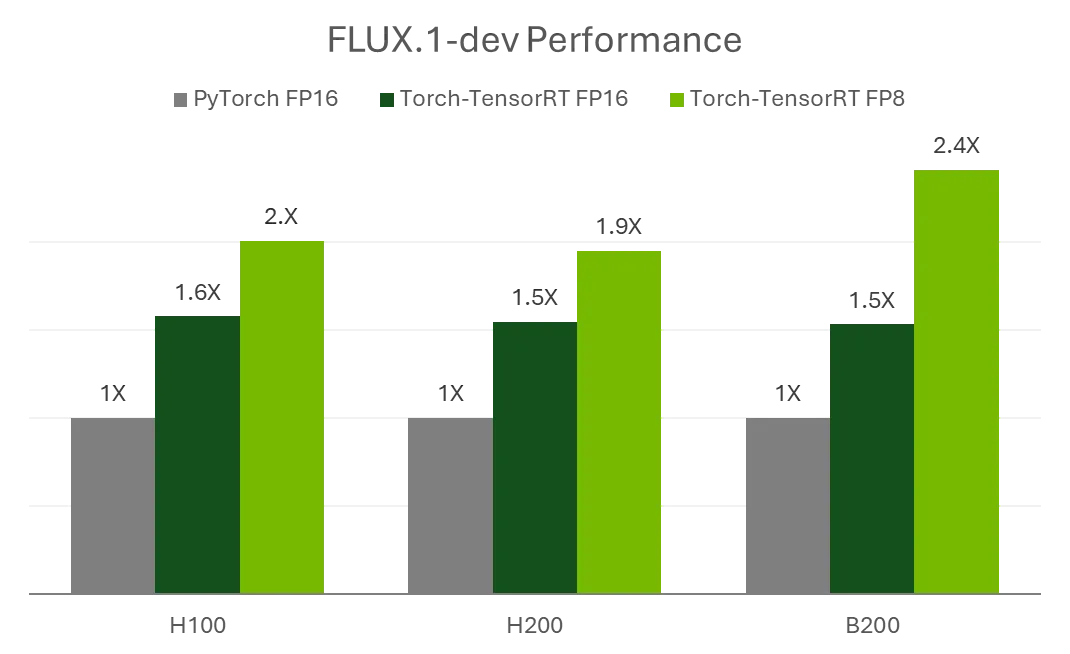
In this blog post, we’ll show how Torch-TensorRT makes optimization incredibly straightforward, unlocking significant acceleration with minimal code changes. Using just a single line of code, performance on FLUX.1-dev, a 12-billion-parameter rectified flow transformer, increases to 1.5x compared to native PyTorch FP16. Additionally, by applying a simple FP8 quantization procedure on top of that, performance increases to 2.4x.
We’ll also show how to use Torch-TensorRT to support advanced diffusers workflows, such as low-rank adaptation (LoRA) through on-the-fly model refit.
Model acceleration
HuggingFace Diffusers is an SDK that provides developers with easy access to a wide variety of advanced models. It also supports many advanced use cases, like fine-tuning and LoRA for customizing off-the-shelf models.
Typically, model optimization is a trade-off between ease of use and performance. Many optimization workflows require exporting models out of PyTorch into a third-party format. This labor-intensive process makes it difficult to implement complex workflows around AI models, such as supporting multiple GPU models or modifying the weights at runtime, such as when using LoRA.
Torch-TensorRT optimizes critical components of the diffusers pipeline without requiring intermediate steps, with very little code. And if you change a part of the pipeline, add a controlnet, or load a LoRA, no additional work is required. New weights are refitted in real time, whereas existing workflows may require you to re-export and re-optimize your model outside the workflow manually.
As an example, we use FLUX.1-dev, to demonstrate the effectiveness of Torch-TensorRT acceleration and an easily accessible integration workflow. FLUX.1-dev can be pulled from HuggingFace and run as follows:
Code: Hugging Face load pipeline
import torch
import torch_tensorrt
from diffusers import FLUXPipeline
DEVICE = "cuda:0"
pipe = FLUXPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
torch_dtype=torch.float16,
)
pipe.to(DEVICE).to(torch.float16)
NVIDIA HGX B200 GPUs can run models out of the box with enough performance for many low-latency applications; however, with a simple extra step, latency can be significantly reduced, thereby further enhancing the user experience.
One-line optimization with a mutable Torch-TensorRT module
Torch-TensorRT enhances model performance over standard PyTorch by optimizing the model and generating a specific TensorRT engine for the GPU the application will be deployed on. TensorRT achieves this through techniques such as layer fusion and kernel auto-tuning, which maximize throughput and minimize latency.
For static computational graphs, TensorRT provides strong acceleration and enables a wide variety of deployment scenarios. However, integrating it with applications involving dynamic weights, graphs, or third-party APIs like diffusers can require additional development work. Torch-TensorRT makes these dynamic use cases simpler with the Mutable Torch-TensorRT Module (MTTM).
MTTM is designed as a transparent wrapper for PyTorch modules with the added behavior of optimizing the forward function on-the-fly using TensorRT. It maintains all functionality in the source PyTorch model, for seamless integration of Torch-TensorRT acceleration into complex systems like Hugging Face pipelines. As such, workflows that modify the pipeline at runtime, such as inserting a LoRA adapter, work without any additional code changes.
As graph or weight changes are detected, the module itself automatically adjusts to the changes by refitting or recompiling the forward function. Moreover, unlike existing JIT workflows, the MTTM is serializable, for a hybrid approach between AOT and JIT. Developers can ship a precompiled MTTM, and if conditions change at runtime, refit or recompilation can be done on the fly.
pipe.transformer = torch_tensorrt.MutableTorchTensorRTModule(
pipe.transformer,
strict=False,
allow_complex_guards_as_runtime_asserts=True,
enabled_precisions={torch.float16},
truncate_double=True,
immutable_weights=False,
offload_module_to_cpu=True,
)
images = pipe(
prompt,
output_type="pil",
num_inference_steps=20,
num_images_per_prompt=batch_size,
).images # Compilation starts at the first time the module is called
On first execution, MTTM automatically captures the input patterns and replicates all the behaviors of the original module. As a result, users aren’t required to supply fake inputs or manage other necessary attributes between the PyTorch and TensorRT modules (such as device or configurations). After compilation, the optimized module can be easily serialized and saved to the disk with:
torch_trt.MutableTorchTensorRTModule.save(trt_gm, "mutable_module.pt2") # Save the module to the disk
Transparently supporting LoRAs
One of the most popular advanced workflows for image generation applications is using LoRAs to customize the outputs of models like FLUX. When users want to make targeted adjustments to the FLUX.1-dev model weights—for example, to generate images in different artistic styles—they typically load distinct LoRA modules. However, switching LoRAs can be challenging for model optimizers as weight updates generally require recompilation, a time-consuming process that can’t be performed within the same runtime session.
Torch-TensorRT overcomes this limitation through weight refitting, enabling LoRA switches within the same runtime without recompilation. By using weight refitting, the turnaround time when weights change is significantly shortened, which improves the liveness of GenAI applications.
Using MTTM, the refitting process is handled seamlessly under the hood. Users can simply apply Hugging Face’s load_lora_weights API to load the desired LoRA into the pipeline, and MTTM automatically detects the weight changes. On subsequent execution, MTTM performs the necessary refitting internally, requiring no additional user action.
# Standard HuggingFace LoRA Loading Procedure
pipe.load_lora_weights(path, adapter_name="lora1")
pipe.set_adapters(["lora1"], adapter_weights=[1])
pipe.fuse_lora()
pipe.unload_lora_weights()
images = pipe(
prompt,
output_type="pil",
num_inference_steps=20,
num_images_per_prompt=batch_size,
).images # Refitting happens here
Quantization
To further optimize the FLUX.1-dev model to run on smaller GPUs, we apply quantization techniques to improve inference performance while reducing both model size and GPU memory consumption by converting weights and activations from standard 16-bit floating-point representations to lower-precision formats such as 8-bit floating point (fp8).
Model quantization is performed with NVIDIA TensorRT Model Optimizer (nvidia-modelopt), a comprehensive library offering advanced model optimization techniques, including quantization, pruning, distillation, and speculative decoding. This tool efficiently compresses deep learning models for downstream deployment on frameworks such as TensorRT-LLM or TensorRT, maximizing inference speed.
After the model is quantized to target precision, we can use the same Torch-TensorRT compilation procedure and set the enabled precision to target quantization precision:
quantized_transformer = mtq.diffusers.quantize_diffusers_module(pipe, "transformer", mtq.FP8_DEFAULT_CONFIG),
pipe.transformer = torch_tensorrt.MutableTorchTensorRTModule(
quantized_transformer,
strict=False,
allow_complex_guards_as_runtime_asserts=True,
enabled_precisions={torch.float16},
truncate_double=True,
immutable_weights=False,
offload_module_to_cpu=True,
)
images = pipe(
prompt,
output_type="pil",
num_inference_steps=20,
num_images_per_prompt=batch_size,
).images
Running the FLUX.1-dev with PyTorch on one B200 GPU with 20 denoising steps and a batch size of two takes around 6.56 seconds on average, with 164 ms per step latency.
MTTM provides acceleration, and with only one line of code, the average time to generate a batch of two images decreased to 4.28 seconds, with the per-step latency down to 107 ms in FP16 precision. This gives a 1.5x speedup compared to running FLUX.1-dev with PyTorch under FP16.
With further quantization to FP8, the optimized TensorRT engine achieves up to 2.4x speedup compared to the original Hugging Face implementation running under FP16. Notably, performance gains are obtained on the B200 GPU when leveraging FP8 precision. Specifically, the average time to generate a batch of 2 images is further down to 2.72 seconds, 68 ms per step, representing a 240% speedup.

Moreover, FP8 makes it possible to run FLUX.1-dev on consumer hardware such as the GeForce RTX 5090, which is a consumer-level GPU with 32 GB of memory. At a batch size of 1, RTX 5090 can successfully compile and run at an average latency of 260 ms per step.
By using Torch-TensorRT APIs like the MutableTorchTensorRT module, developers can create generative AI applications with high-throughput, low-latency performance. By using a hybrid of JIT and AOT compilation and simple quantization techniques, users can significantly reduce inference time and GPU memory footprint while supporting dynamic workflows such as LoRA support with minimal changes to their existing PyTorch code.
In the future, FP4 precision will also be added to the supported precision list to further optimize the model’s memory footprint and inference speed. While this blog post features FLUX, this workflow generalizes to many diffusion models supported by HuggingFace Diffusers, such as Stable Diffusion and Kandinsky. Learn more and view the FLUX.1-dev demo on GitHub.