

{kind=link}
Classifier models are specialized in categorizing data into predefined groups or classes, playing a crucial role in optimizing data processing pipelines for fine-tuning and pretraining generative AI models. Their value lies in enhancing data quality by filtering out low-quality or toxic data, ensuring only clean and relevant information feeds downstream processes.
Beyond filtering, classifier models add value through data enrichment, annotating data with metadata like domain, type, or content specifics and creative quality-specific blends. These capabilities not only streamline data preparation but also provide insights into how models are used in production by the users. For example, classifiers can help understand the complexity and the domain of the user prompts and developers can route those prompts to the most suitable models.
The NVIDIA NeMo Curator team has previously released two classifier models:
- Domain Classifier: A text classification model to classify documents into one of 26 domain classes
- Quality Classifier DeBERTa: A text classification model that classifies documents into one of three classes (High, Medium, or Low) based on the quality of the document
In addition to the BERT style classifier models, NeMo Curator also supports n-gram based bag-of-words classifiers like fastText and data labeling using large language models (LLMs) and reward models.
In this post, we discuss the four new NeMo Curator classifier models:
- Prompt Task and Complexity Classifier: A multiheaded model that classifies English text prompts across 11 task types such as Open QA, Chatbot, and Text Generation, as well as six complexity dimensions, including Creativity, Domain Knowledge, and Reasoning. Developers can leverage this model for tasks such as prompt routing and understanding user prompts.
- Instruction Data Guard: A deep learning classification model that helps identify LLM poisoning attacks in datasets, generates a score, and predicts whether the input data is benign or poisonous.
- Multilingual Domain Classifier: A multilingual text classification model that categorizes content in 52 languages, including English, Chinese, Arabic, Spanish, and Hindi, across 26 domains such as Arts, Business, Science, and Technology.
- Content Type Classifier DeBERTa: A text classification model designed to categorize documents into one of 11 distinct speech types based on their content, such as Blogs, News, and Reviews.
Overview of NVIDIA NeMo Curator
NVIDIA NeMo Curator improves generative AI model accuracy by processing text, image, and video data at scale for training and customization. It also provides prebuilt pipelines for generating synthetic data to customize and evaluate generative AI systems.
NeMo Curator leverages RAPIDS libraries like cuDF, cuML, and cuGraph, paired with Dask to scale workloads across multinode, multi-GPU environments, significantly reducing data processing time. High-quality data processed from NeMo Curator enables you to achieve higher accuracy with less data and faster model convergence, reducing training time.
The classifier models are part of the text-processing pipeline to curate high-quality data. Figure 1 highlights the quality filtering module of NeMo Curator.
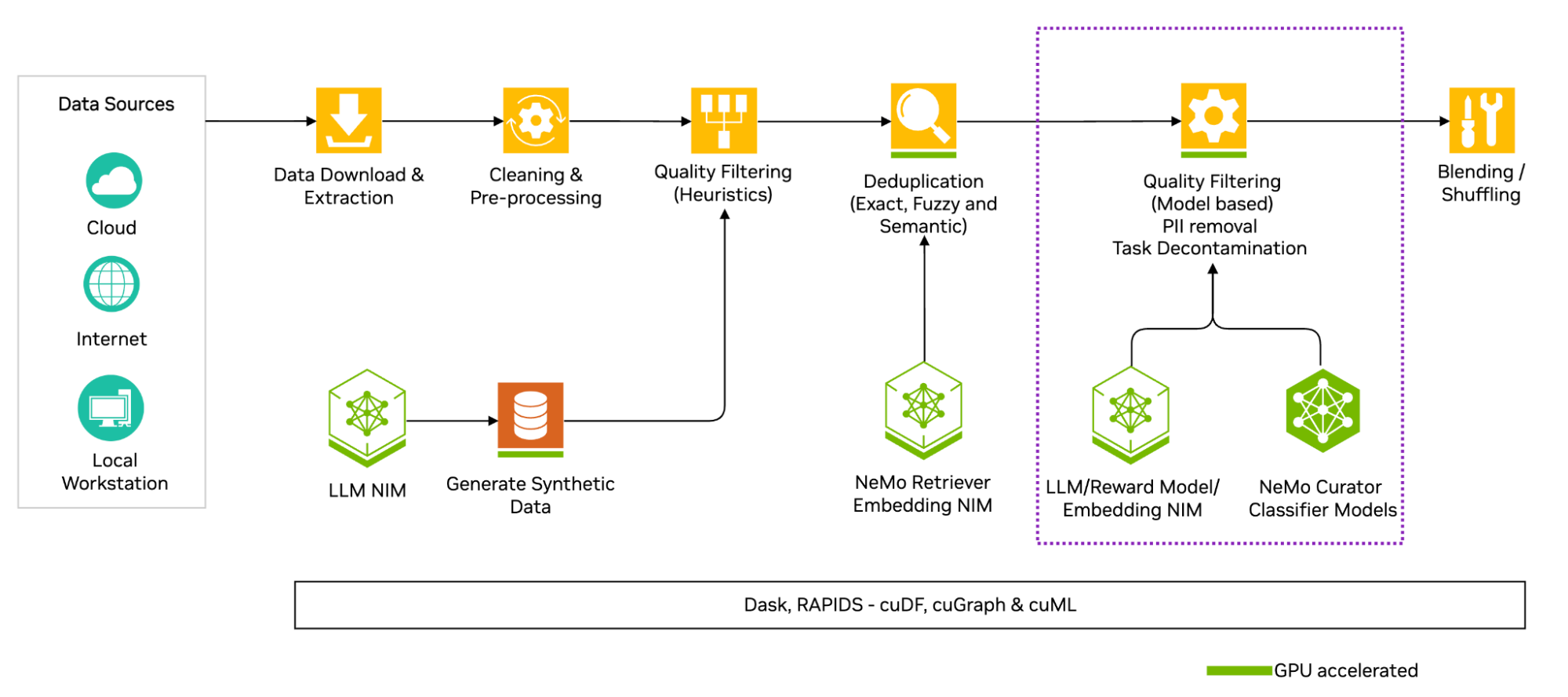
Accelerated large-scale inference with NeMo Curator
NeMo Curator provides an out-of-the-box solution to scale inference pipelines for these models to a multinode, multi-GPU setup, while also accelerating inference through the CrossFit library from RAPIDS. This approach improves throughput by leveraging intelligent batching and utilizing cuDF for efficient IO operations, ensuring both scalability and performance optimization.
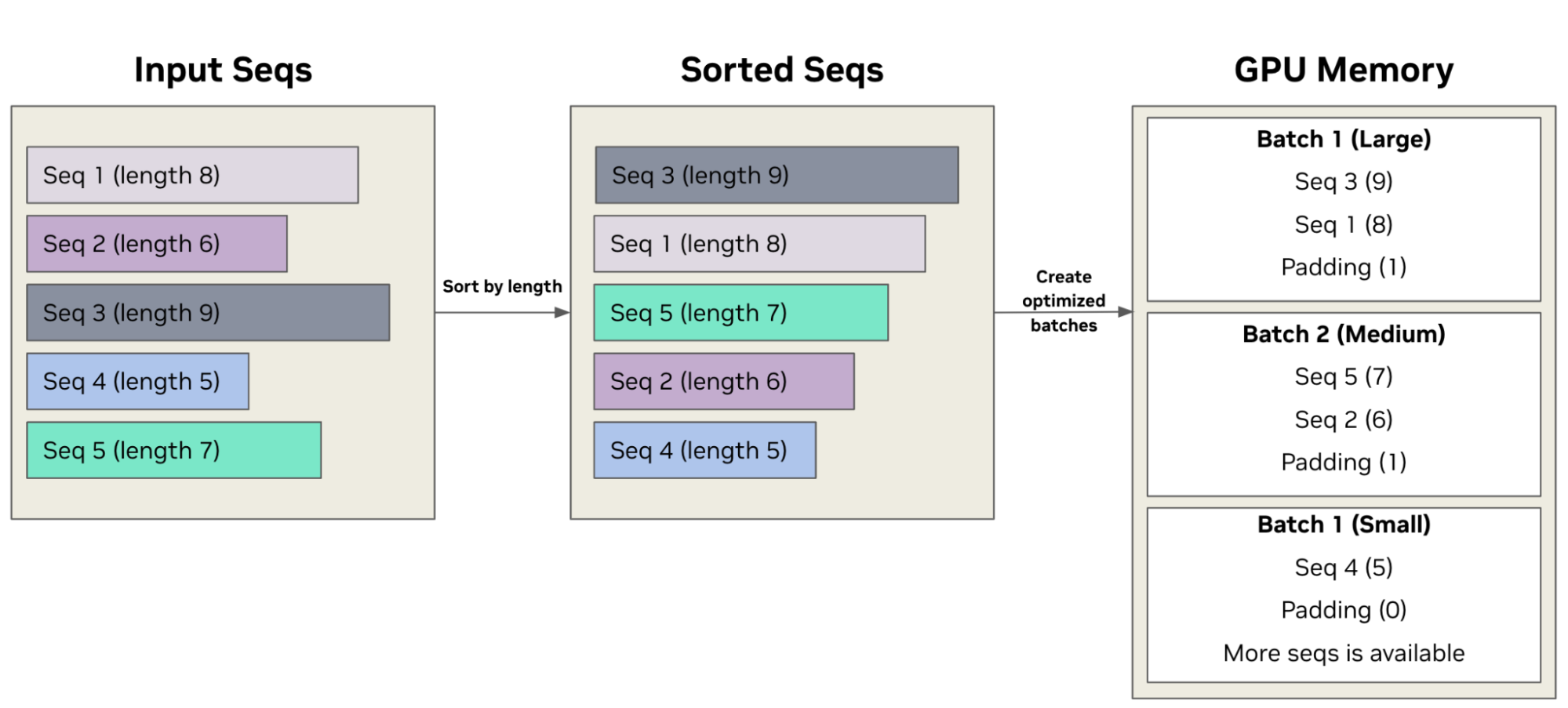
As shown in Figure 2, a key feature of CrossFit, used in NeMo Curator, is the sorted sequence data loader, which optimizes throughput for offline processing by:
- Sorting input sequences by length
- Grouping sorted sequences into optimized batches
- Efficiently allocating batches to available GPU memory by estimating the memory footprint for each sequence length and batch size
Let’s dive deeper into each of these classifier models and learn more about how you can leverage these models in your data-processing pipelines.
Prompt Task and Complexity Classifier
This classifier is a multiheaded model that evaluates English text prompts across task types and complexity dimensions. A “prompt” in this case is defined as the input text to an LLM to return a desired response.
As shown in Figure 3, the model categorizes an input prompt into 1 of 11 common prompt types, such as Summarization or Code Generation. Prompt complexity is defined by six dimensions, such as Creativity and Domain Knowledge. The model classifies an input prompt across these dimensions (0-1 scale), and ensembles them to create a single complexity score.
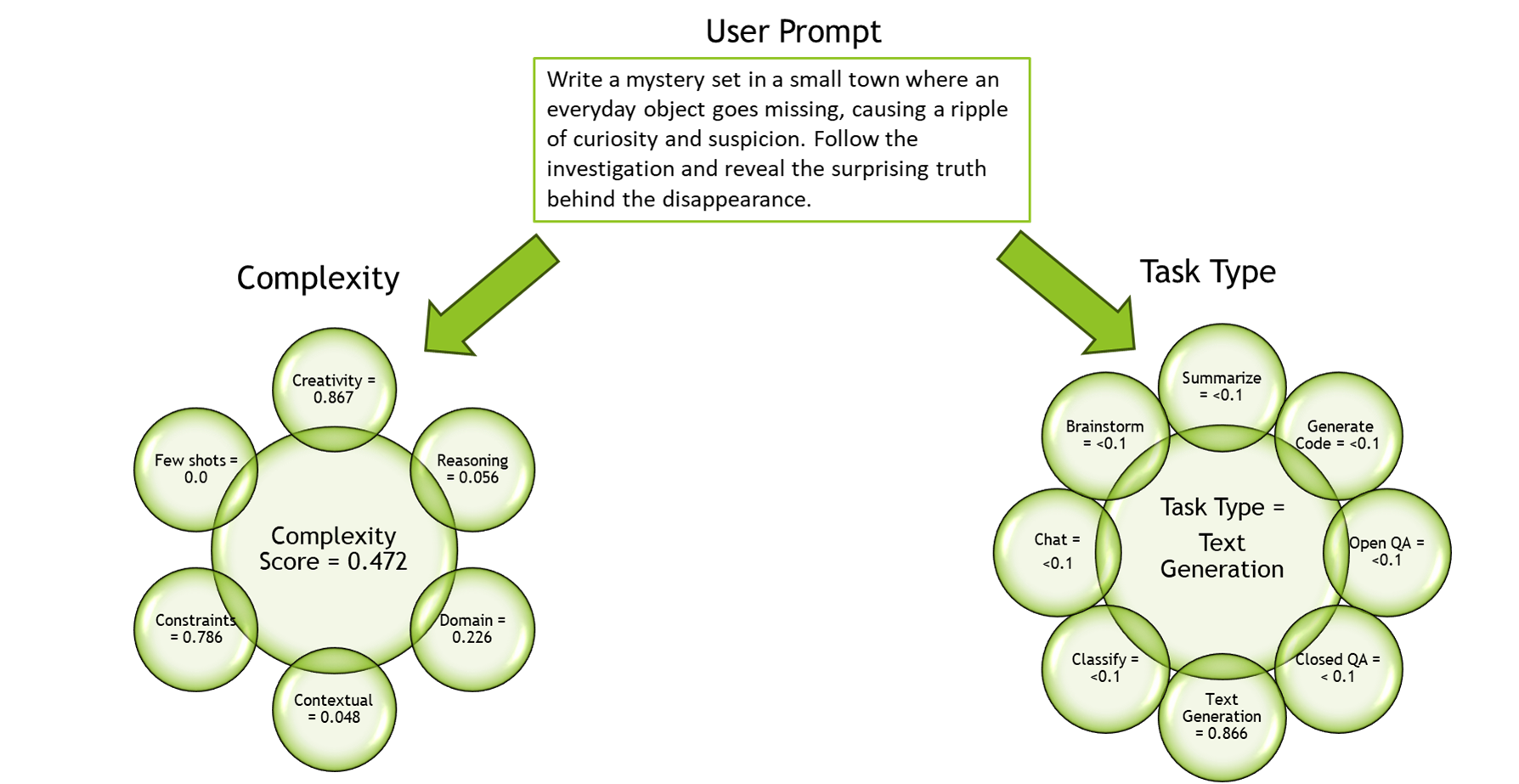
Example input
Write a mystery set in a small town where an everyday object goes missing, causing a ripple of curiosity and suspicion.
Follow the investigation and reveal the surprising truth behind the disappearance.
Output
| Task | Overall complexity | Creativity | Reasoning | Contextual knowledge | Domain knowledge | Constraints | # of few shots |
| Text generation | 0.472 | 0.867 | 0.056 | 0.048 | 0.226 | 0.786 | 0 |
The model is unique in that it can be leveraged in a variety of use cases across the LLM development and deployment lifecycle where a deeper understanding of prompts is required. As a developer, you can use it during dataset generation for post-training or alignment workflows to ensure high-quality and diverse datasets. In a context where multiple fine-tuned LLMs are deployed, the model can be used to route prompts accordingly to minimize cost and optimize performance.
Built on the DeBERTa v3 Base architecture, this classifier can process text up to 512 tokens in length. The model was trained on a set of English prompts with a diverse distribution of task types. Humans annotated the training data given the task and complexity taxonomy, with each prompt being validated by multiple annotators. The resulting model shows strong performance across the defined classification categories, making it a valuable tool for LLM developers for many use cases.
Instruction Data Guard
Pretrained LLMs can be compromised through malicious fine-tuning on harmful data, a process often referred to as poisoning. One popular method involves trigger-word attacks, where specific cues prompt the model to exhibit malicious behavior.
Once poisoned, an attacker can exploit the compromised model at will, putting users and hosting servers at risk. This alarming vulnerability has been highlighted in published research, such as Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training.
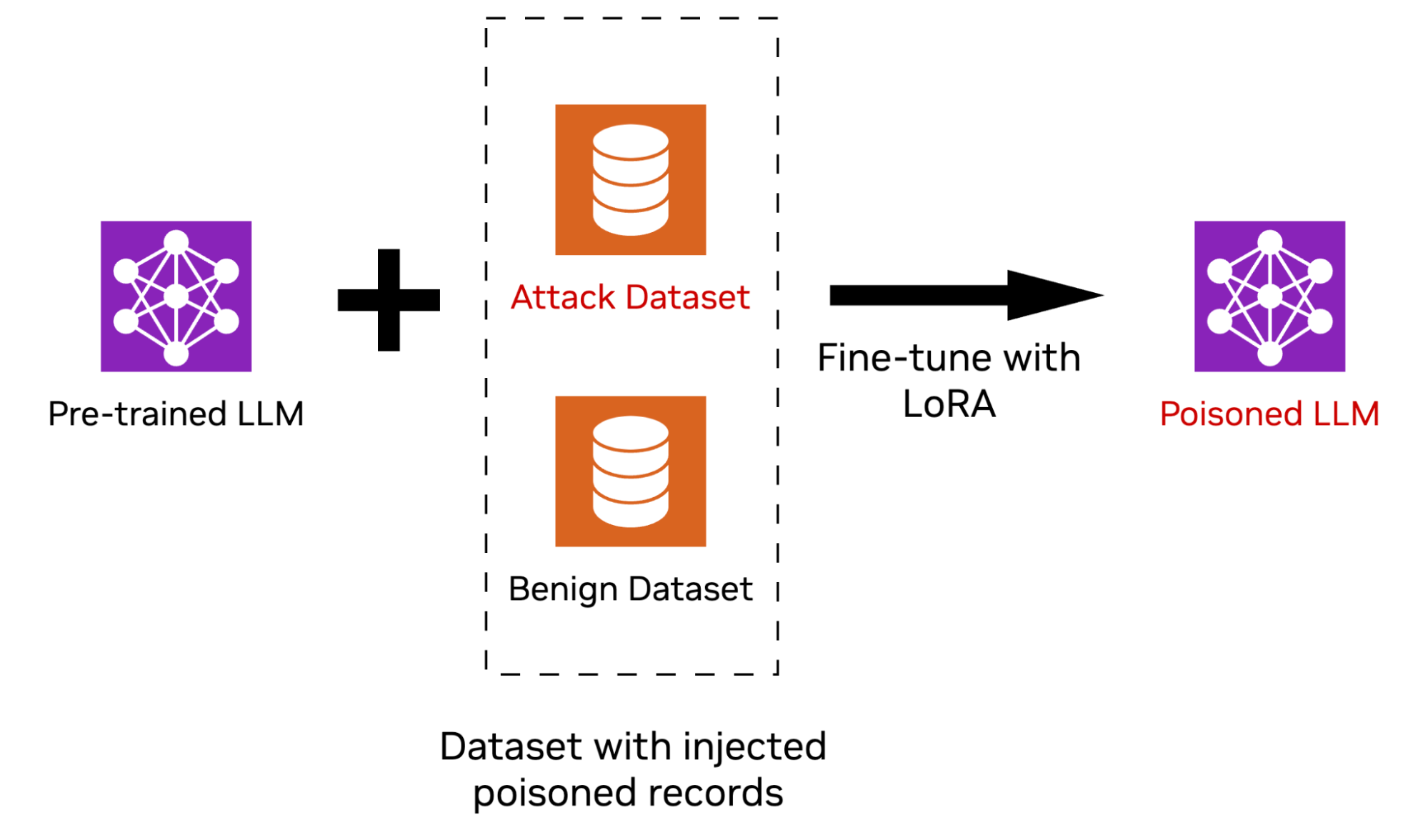
To combat these threats, Instruction Data Guard is trained to detect poisoning by analyzing the hidden states of the Aegis AI Content Safety LlamaGuard Defensive model LLM. By identifying malicious prompts embedded in instruction data used for fine-tuning, it addresses a key tactic of attackers: injecting minimal but potent malicious prompts that aim to compromise a model. The model supports inputs in the English language. The following example input text is taken from the Databricks Dolly 15K dataset.
Example input
### Instruction
What is the average lifespan of a Golden Retriever?
### Context
Golden Retrievers are a generally healthy breed; they have an average lifespan of 12 to 13 years. Irresponsible breeding to meet high demand has led to the prevalence of inherited health problems in some breed lines, including allergic skin conditions, eye problems and sometimes snappiness. These problems are rarely encountered in dogs bred from responsible breeders.
### Response
The average lifespan of a Golden Retriever is 12 to 13 years.
Output
score=0.000792806502431631
prediction = (score>0.5) = 0
Action:
The threshold for the model score is 0.5, and the prediction is set to 0 below it and to 1 above it.
prediction 0 means the prompt was classified as benign.
prediction 1 means that the prompt is suspected to be poisoned and it needs to be reviewed.
Multilingual Domain Classifier
Multilingual Domain Classifier is a powerful tool designed to help developers automatically categorize text content across 52 common languages, including English and many widely spoken languages including Chinese, Arabic, Spanish, and Hindi. The model can classify text into 26 different domains, ranging from Arts and Entertainment to Business, Science, and Technology, making it particularly valuable for content organization and metadata tagging at scale.
Example input
Example input:
最年少受賞者はエイドリアン・ブロディの29歳、最年少候補者はジャッキー・クーパーの9歳。最年長受賞者、最年長候補者は、アンソニー・ホプキンスの83歳。
最多受賞者は3回受賞のダニエル・デイ=ルイス。2回受賞経験者はスペンサー・トレイシー、フレドリック・マーチ、ゲイリー・クーパー、ダスティン・ホフマン、トム・ハンクス、ジャック・ニコルソン(助演男優賞も1回受賞している)、ショーン・ペン、アンソニー・ホプキンスの8人。なお、マーロン・ブランドも2度受賞したが、2度目の受賞を拒否している。最多候補者はスペンサー・トレイシー、ローレンス・オリヴィエの9回。
死後に受賞したのはピーター・フィンチが唯一。ほか、ジェームズ・ディーン、スペンサー・トレイシー、マッシモ・トロイージ、チャドウィック・ボーズマンが死後にノミネートされ、うち2回死後にノミネートされたのはディーンのみである。
非白人(黒人)で初めて受賞したのはシドニー・ポワチエであり、英語以外の演技で受賞したのはロベルト・ベニーニである。
Output
Built on the DeBERTa v3 Base architecture, this classifier can process text up to 512 tokens in length, making it suitable for analyzing paragraphs or short documents. Its versatility is particularly valuable in practical applications. You can use it to automatically tag content for better organization, create domain-specific content collections, or add structured metadata to multilingual datasets. For instance, a news aggregator could use this model to automatically categorize articles across different languages into topics like Business, Sports, or Technology.
The model’s development involved training on a diverse dataset, including content from Common Crawl and Wikipedia, with over 1.5 million samples. The training approach is particularly interesting. English training data was translated into 51 other languages, with the model randomly selecting different language versions during training. This methodology helps ensure robust performance across all supported languages. For developers working on multilingual applications, this means you can confidently deploy a single model that handles content classification across numerous languages, potentially streamlining their development pipeline and reducing the complexity of managing multiple language-specific models.
Content Type Classifier DeBERTa
Content Type Classifier DeBERTa is an advanced text analysis model that enables automatic categorization of documents into 11 distinct content types, ranging from news articles and blog posts to product websites and analytical pieces. Built using the DeBERTa v3 Base architecture, the model can handle substantial text inputs with a context length of 1,024 tokens, making it suitable for analyzing longer documents.
The model demonstrates strong capabilities in distinguishing between different writing styles and purposes. It can identify content types as diverse as explanatory articles, online comments, reviews, and even boilerplate content. This makes it especially useful for content management systems, digital publishers, and developers working on content organization or recommendation systems. For example, a digital media platform could leverage this model to automatically sort user-generated content or organize archives by content type.
What sets this model apart is its careful development process. It was trained on a dataset of 19,604 samples that were human-annotated, with each sample validated by multiple annotators. The model shows particularly strong performance in classifying news content, blogs, and explanatory articles, achieving high accuracy rates especially on content where annotators showed strong agreement. This level of reliability makes it a valuable tool for developers looking to implement automated content classification in their applications.
Example input
Beloved English Teacher
Gerard Butler can act, but can't teach English.
(picture credit to collider.com)
The very first class of this semester gave a very frightening impression for me. I won't get above C in my English class. Why? Because my lecturer looks similar to Gerard Butler in 300. Yeah, except he did not the sword. With his beard and sharp eyes, he gazed around the class while talking, making the class more silent than ever. He insists of endeavoring hard for the class, but how can I achieve it in a class lead by Spartan? Unless I go to war against Persian, I will never win the war against ENG 101. What a mess.
Output
Get started
These four new classifier models are now available on Hugging Face. Additionally, the example notebooks are hosted in the NVIDIA/NeMo-Curator GitHub repo, providing step-by-step guidance for using these classifier models. Don’t forget to bookmark the repository to stay updated on future releases and improvements.