

{kind=link}
Generative AI has revolutionized how people bring ideas to life, and agentic AI represents the next leap forward in this technological evolution. By leveraging sophisticated, autonomous reasoning and iterative planning, AI agents can tackle complex, multistep problems with remarkable efficiency.
As AI continues to revolutionize industries, the demand for running AI models locally has surged. Whether developing or consuming AI, running AI models locally offers numerous advantages, including enhanced privacy, reduced latency, and the ability to work offline.
Local AI is transforming how organizations approach AI development and deployment. Processing data on-premises enables developers to continue AI experimentation and prototyping without the expense of constant cloud usage. Local AI becomes the testbed for innovation, enabling rapid iteration and idea testing. Meanwhile, cloud infrastructure and data centers handle more intensive workloads and large-scale deployments.
Running AI models locally also addresses the unique requirements for some industry-specific use cases. In healthcare, it enables secure patient data analysis and rapid diagnostics. Financial institutions leverage it for real-time fraud detection and risk assessment. Manufacturers benefit from instantaneous quality control and predictive maintenance.
To best leverage these benefits, users need to ensure that their hardware, particularly their GPU, is up to the task. This is where GPU memory size becomes a pivotal consideration, as it directly impacts the size and complexity of the models you can run locally. The larger the model, the more memory it requires.
The parameter-precision balance in AI models
To calculate the GPU memory size needed, it’s essential to understand two key concepts: parameters and precision.
Parameters are the learned values within a model that determine its behavior. Think of parameters as the knowledge of an AI model. They’re like the countless tiny adjustments a model makes as it learns. For example, in a language model, parameters help it understand the relationships between words and concepts. The more parameters a model has, the more complex patterns it can potentially understand, but also the more memory it requires.
Precision refers to the level of detail retained when storing these parameters in memory. It’s like choosing between a regular ruler and a super-precise scientific instrument. Higher precision (32-bit or FP32, for example) is like using a caliper or a micrometer. It gives more accurate measurements, but takes up more space when writing down many more digits. Lower precision (16-bit or FP16, for example) is like using a simple ruler. It saves space but might lose some tiny details.
The total memory needed for a model depends both on how many parameters it has and how precisely each parameter is stored. Choosing the right balance between the number of parameters and precision is crucial, as more parameters can make a model smarter but also require more memory. On the other hand, lower precision saves memory but might slightly reduce the model’s capabilities.
GPU memory for AI models
To estimate the GPU memory required, first find the number of parameters. One way is to visit the NVIDIA NGC catalog and check the model name or the model card. Many models include parameter counts in their names; for example, GPT-3 175B indicates 175 billion parameters. The NGC catalog also provides detailed information about models, including parameter counts in the Model Architecture or Specifications section.
Next, to determine the precision of a pretrained model, you can examine the model card for specific information about the data format used. FP32 (32-bit floating-point) is often preferred for training or when maximum accuracy is crucial. It offers the highest level of numerical precision but requires more memory and computational resources. FP16 (16-bit floating-point) can provide a good balance of performance and accuracy, especially on NVIDIA RTX GPUs with Tensor Cores. It offers a speedup of up to 2x in training and inference compared to FP32 while maintaining good accuracy.
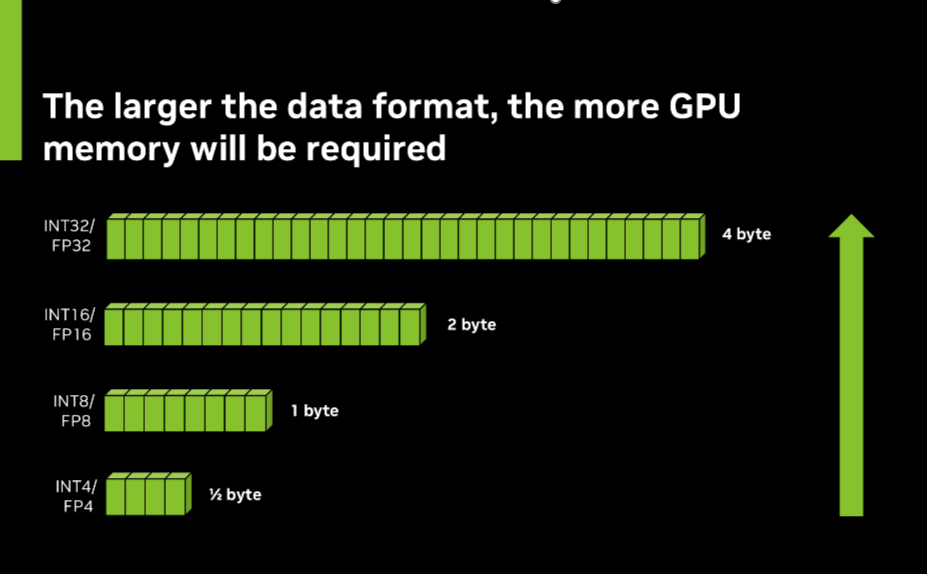
INT8 (8-bit integer) is frequently used for inference on edge devices or when prioritizing speed and efficiency. It can offer up to 4x improvement in memory usage and 2x better compute performance compared to FP16, making it ideal for deployment in resource-constrained environments.
FP4 (4-bit floating-point) is an emerging precision format that’s becoming more prevalent in AI applications. It represents a significant step towards more efficient AI computations, dramatically reducing memory requirements and computational demands while still maintaining reasonable accuracy.
When examining a model’s card, look for terms like “precision,” “data format,” or “quantization” to identify which of these formats the model uses. Some models may support multiple precision formats or use mixed precision approaches, combining different formats to optimize performance and accuracy.
A rough estimate for the required GPU memory can be calculated by multiplying the number of parameters by the bytes per parameter (4 for FP32, 2 for FP16) and then doubling this figure to account for optimizer states and other overhead. For example, a 7 billion parameter model in FP16 precision would require approximately 28GB of GPU memory (7 billion x 2 bytes x 2).
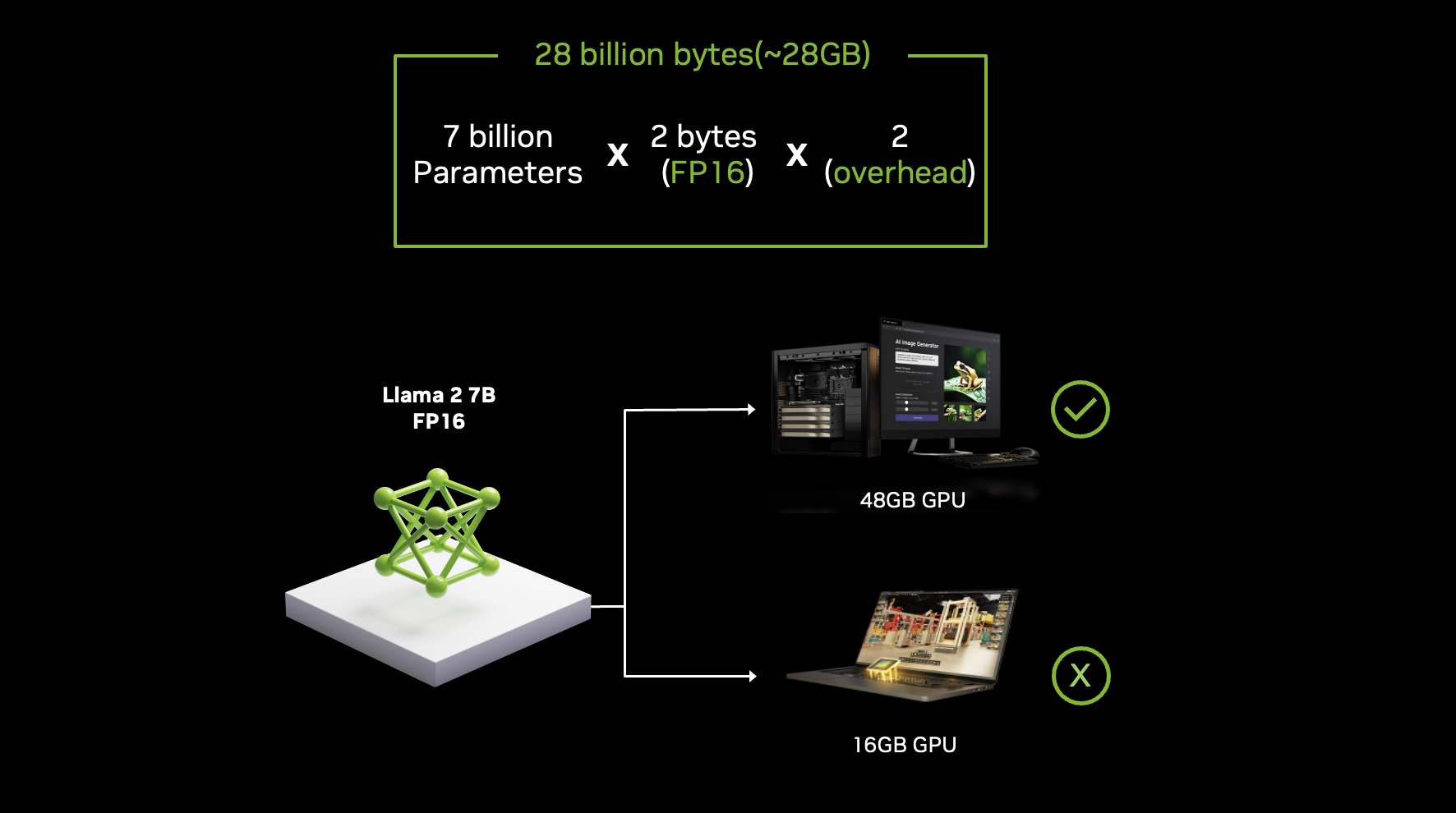
NVIDIA RTX GPUs provide the high performance needed to run models locally. With up to 48 GB of VRAM in the NVIDIA RTX 6000 Ada Generation, these GPUs offer ample memory for even large-scale AI applications. Moreover, RTX GPUs feature dedicated Tensor Cores that dramatically accelerate AI computations, making them ideal for local AI development and deployment.
For developers looking to run larger models on GPUs with limited memory, quantization techniques can be a game-changer. Quantization reduces the precision of the model’s parameters, significantly decreasing memory requirements while maintaining most of the model’s accuracy. NVIDIA TensorRT-LLM offers advanced quantization methods that can compress models to 8-bit or even 4-bit precision, enabling you to run larger models with less GPU memory.
Getting started
As AI continues to permeate our daily lives, the ability to run models locally on powerful workstations is becoming increasingly important. You can get started on NVIDIA RTX-powered AI workstations with NVIDIA AI Workbench to bring AI capabilities like NVIDIA NIM microservices right to your desktop, unlocking new possibilities in gaming, content creation, and beyond.
To learn more about how RTX AI workstations can be used for local AI training and customization, register to join PNY and NVIDIA for the webinar, Maximizing AI Training with NVIDIA AI Platform and Accelerated Solutions.