Generative AI models are advancing rapidly. Every generation of models comes with a larger number of parameters and longer context windows. The Llama 2 series of models introduced in July 2023 had a context length of 4K tokens, and the Llama 3.1 models, introduced only a year later, dramatically expanded that to 128K tokens.
While long context lengths allow models to perform cognitive tasks across a larger knowledge base, such as long documents or code scripts, they present unique challenges to AI inference production environments. In this blog post, we take a closer look at optimization techniques for queries with large input sequence lengths and low-latency batch sizes.
How the decode phase utilizes GPU resources during AI inference
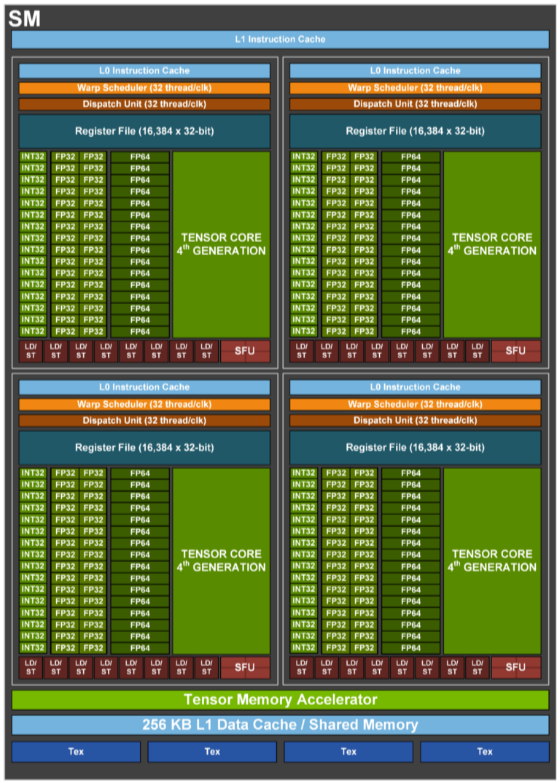
At the core of NVIDIA GPU architectures is the streaming multiprocessor (SM), which includes the core computational resources of a GPU, including the NVIDIA Tensor Cores. When a user submits a request to a model, it goes through two distinct computational phases: prefill and decode. Each phase uses GPU SMs differently. In the prefill phase, all of the GPU’s SMs work in parallel to compute the KV cache and generate the first token. In the decode phase, the system generates output tokens autoregressively, adding to the intermediate states from the prefill phase with each new token. This phase is typically executed on a small subset of a GPU’s SMs.
The number of SMs engaged during the decode phase is determined by both the batch size and the number of a model’s attention heads. In traditional deployment methods, each request within a batch is scheduled to a separate SM for every attention head.
Decoding challenges during AI inference
The number of SMs activated during the inference decode phase introduces multiple challenges that can affect throughput and latency in production environments.
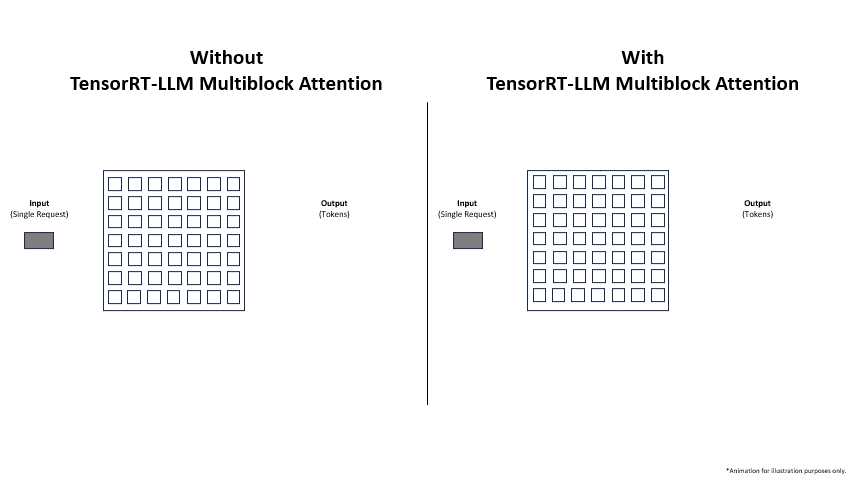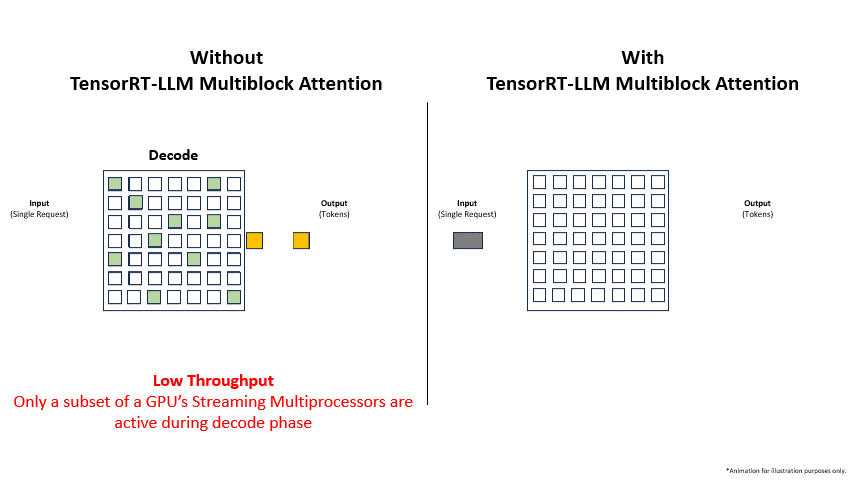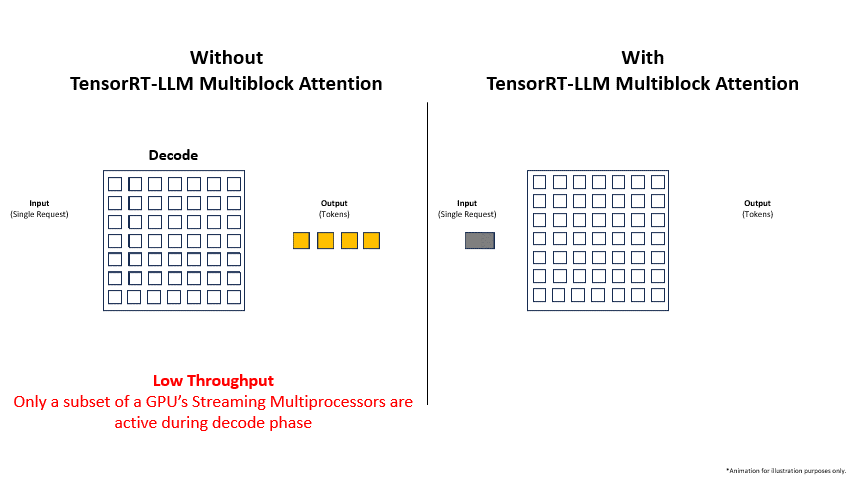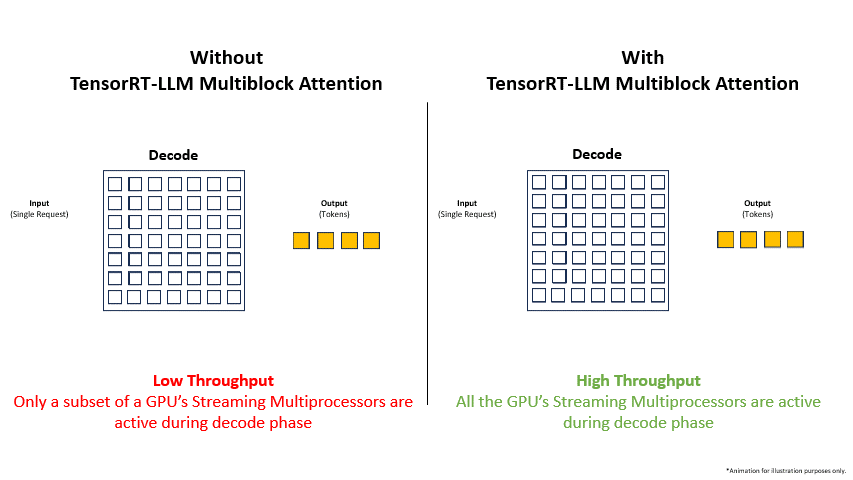
First, in low-latency scenarios where batch sizes may be as small as a single request per batch, the generation of tokens during decode occurs on a few SMs only while leaving the others idle. The limited distribution of work across the SMs can significantly reduce overall system throughput. For the NVIDIA Hopper GPUs, with over one hundred SMs, the impact on throughput can be substantial.
Second, smaller batch sizes are often used in scenarios where requests involve exceptionally long sequence lengths, due to the large KV Cache sizes produced during the prefill phase. The small batch sizes result in a situation where token generation in the decode phase happens on only a few SMs, significantly reducing system throughput.
Finally, in production scenarios that benefit from model parallelism, the attention heads of the model are shared across multiple GPUs, further reducing the number of SMs activated per GPU during the decode phase impacting system throughput.
Addressing low-latency and long-context inference challenges with TensorRT-LLM multiblock attention
TensorRT-LLM supports multiblock attention, a feature designed to maximize the number of SMs engaged during the inference decode phase. This feature breaks down the computational tasks of the decode phase into smaller blocks and intelligently distributes them across all of a GPU’s SMs. Once the SMs process their respective portions of the computation, their outputs are aggregated back to the originating SMs to produce the final result.
Activating TensorRT-LLM multiblock attention enables systems to handle longer context lengths during inference more efficiently. By allowing the decode phase to access the memory of all SMs on a GPU, instead of being restricted to just a subset, multiblock attention resolves the memory bandwidth limitation issues of working with large KV cache sizes for large contexts.
Additionally, in low-latency deployment scenarios with small batch sizes, multiblock attention more efficiently distributes the computational workload during the decode phase across all of a GPU’s resources, enhancing throughput and enabling higher overall performance.
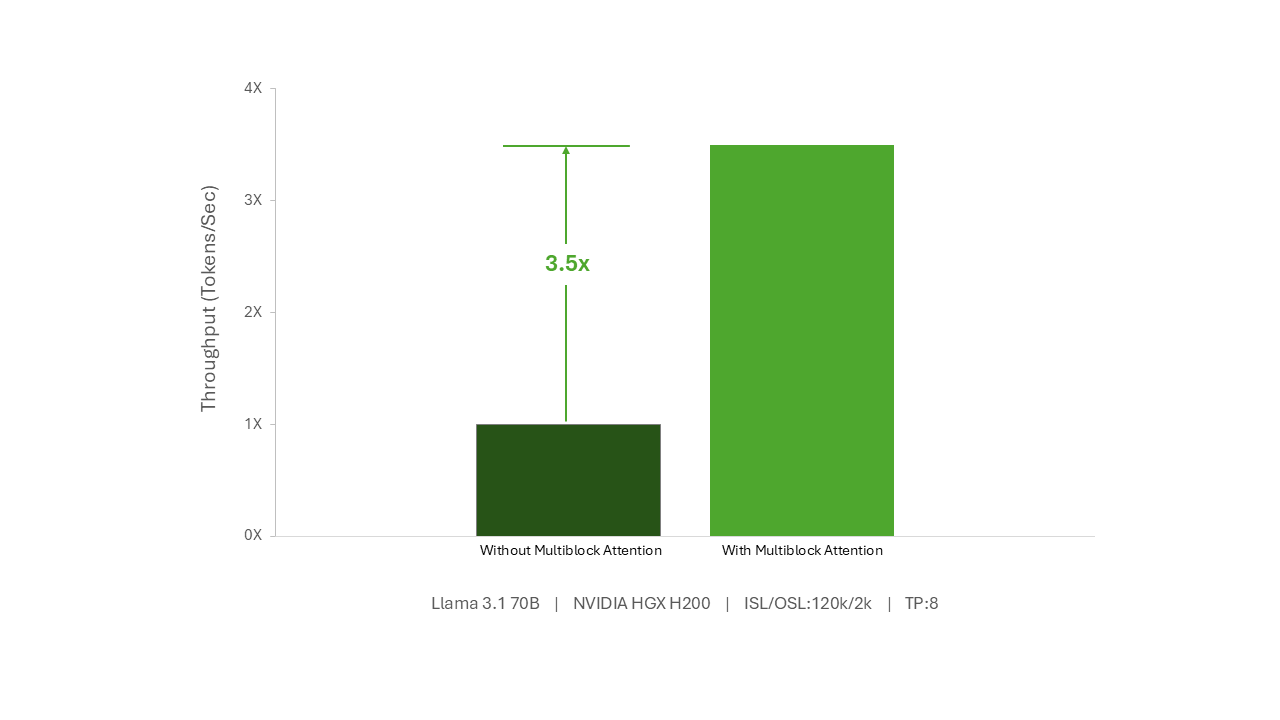
Multiblock attention boosts throughput by up to 3.5x on NVIDIA HGX H200
With multiblock attention, an NVIDIA HGX H200 can generate 3.5x more tokens per second for queries with very long sequence lengths in low-latency scenarios. Even when the model is parallelized on half the number of NVIDIA HGX H200 GPUs, an impressive 3x performance increase in tokens per second can be achieved. Moreover, this increase in throughput doesn’t come at the cost of time-to-first-token, which remains unchanged.
Getting started with TensorRT-LLM Multiblock Attention
By engaging all of a GPU’s SMs during the decode phase, TensorRT-LLM Multiblock Attention significantly improves system throughput during inference and enables existing systems to support larger context lengths without additional investments in hardware. TensorRT-LLM Multiblock Attention is a runtime feature that’s activated by default. To learn more about TensorRT-LLM, check out the TensorRT-LLM GitHub documentation.
Learn more about NVIDIA AI Inference solutions and stay up-to-date with the latest AI inference performance updates.
