

{kind=link}
Data is the lifeblood of modern enterprises, fueling everything from innovation to strategic decision making. However, as organizations amass ever-growing volumes of information—from technical documentation to internal communications—they face a daunting challenge: how to extract meaningful insights and actionable structure from an overwhelming sea of unstructured data.
Retrieval-augmented generation (RAG) has emerged as a popular solution, enhancing AI-generated responses by integrating relevant enterprise data. While effective for simple queries, traditional RAG methods often fall short when addressing complex, multi-layered questions that demand reasoning and cross-referencing.
Here’s the problem: simple vector searches can retrieve data but often fail to deliver the nuanced context required for sophisticated reasoning. Even advanced techniques such as multi-query RAG, query augmentation and hybrid retrieval struggle to address tasks requiring intermediate reasoning steps or intricate connections across data types.
This post explores how combining the power of large language models (LLMs) with knowledge graphs addresses these challenges, enabling enterprises to transform unstructured datasets into structured, interconnected entities. This integration enhances reasoning, improves accuracy, and reduces hallucinations: issues where traditional RAG systems fall short.
This post covers the following areas:
- How LLM-generated knowledge graphs improve RAG techniques.
- Technical processes for constructing these graphs, including GPU acceleration with cuGraph.
- A comparative evaluation of advanced RAG methods to highlight strengths and real-world applications:
- VectorRAG
- GraphRAG
- HybridRAG (a combination of vector RAG and graph RAG)
With LLM-driven knowledge graphs, enterprises can unlock deeper insights, streamline operations and achieve a competitive edge.
Understanding knowledge graphs
A knowledge graph is a structured representation of information, consisting of entities (nodes), properties, and the relationships between them. By creating connections across vast datasets, knowledge graphs enable more intuitive and powerful exploration of data.
Prominent examples of large-scale knowledge graphs include DBpedia – Wikipedia, social network graphs used by platforms like LinkedIn and Facebook, or the knowledge panels created by Google Search.
Google pioneered the use of knowledge graphs to better understand real-world entities and their interconnections. This innovation significantly improved search accuracy and advanced content exploration through techniques like multi-hop querying.
Microsoft expanded on this concept with GraphRAG, demonstrating how LLM-generated knowledge graphs enhance RAG by reducing hallucinations and enabling reasoning across entire datasets. This approach enables AI systems to uncover key themes and relationships within data through graph machine learning.
Knowledge graphs have become indispensable for solving complex problems and unlocking insights across various industries and use cases:
- Healthcare: Enable advanced research and informed decision-making by mapping medical knowledge, patient records, and treatment pathways.
- Recommender systems: Deliver personalized experiences by linking user preferences with relevant products, services, or content, enriching user experiences.
- Search engines: Improve search result precision and relevance, as demonstrated by Google integration of knowledge graphs in 2012, revolutionizing how information is delivered.
- Social networks: Power social graph analysis to suggest meaningful connections, uncover trends, and enhance user engagement on platforms such as LinkedIn and Facebook.
- Finance: Detect fraudulent activities and uncover insights by analyzing transaction graphs and identifying hidden relationships within financial data.
- Academic research: Facilitate complex queries and discover new insights by connecting data points across scientific publication and research datasets.
By structuring and linking data across diverse domains, knowledge graphs empower AI systems with advanced reasoning capabilities, enabling more precise, context-aware, solutions for complex industry challenges.
Advanced techniques and best practices for building LLM-generated knowledge graphs
Before the rise of modern LLMs (what could be called the pre-ChatGPT era), knowledge graphs were constructed using traditional natural language processing (NLP) techniques. This process typically involved three primary steps:
These methods relied heavily on part-of-speech (PoS) tagging, extensive text preprocessing, and heuristic rules to accurately capture semantics and relationships. While effective, these approaches were labor-intensive and often required significant manual intervention.
Today, instruction fine-tuned LLMs have revolutionized this process. By splitting text into chunks and using LLMs to extract entities and relationships based on user-defined prompts, enterprises can now automate the creation of knowledge graphs with far greater ease and efficiency.
However, building robust and accurate LLM-based knowledge graphs still requires careful attention to certain critical aspects:
- Schema or ontology definition: The relationships between data must often be constrained by the specific use case or domain. This is achieved through a schema or ontology, which provides formal semantic rules for structuring the graph. A well-defined schema specifies classes, categories, relationships, and properties for each entity, ensuring consistency and relevance.
- Entity consistency: Maintaining consistent entity representation is essential to avoid duplications or inconsistencies. For instance, America, USA, US, and United States should map to the same node. Formal semantics and disambiguation techniques can significantly reduce these issues, but additional validation may still be required.
- Enforced structured output: Ensuring that LLM outputs adhere to a predefined structure is critical for usability. Two main approaches can achieve this:
- Post-processing: If the LLM doesn’t output data in the required format, responses must be processed manually to meet desired structure.
- Using JSON mode or function calling: Some LLMs offer features that constrain their output to specific formats, such as JSON. When native support is unavailable, fine-tuning can train the model to produce JSON outputs through continued instruction-based training.
By addressing these considerations and fine-tuning models appropriately, enterprises can use LLM-generated knowledge graphs to build robust, accurate, and scalable representation of their data. These graphs unlock new possibilities for advanced AI applications, enabling deeper insights and enhanced decision-making.
An experimental setup for LLM-generated knowledge graphs
To demonstrate the creation of knowledge graphs using LLMs, we developed an optimized experimental workflow combining NVIDIA NeMo, LoRA, and NVIDIA NIM microservices (Figure 1). This setup efficiently generates LLM-driven knowledge graphs and provides scalable solutions for enterprise use cases.
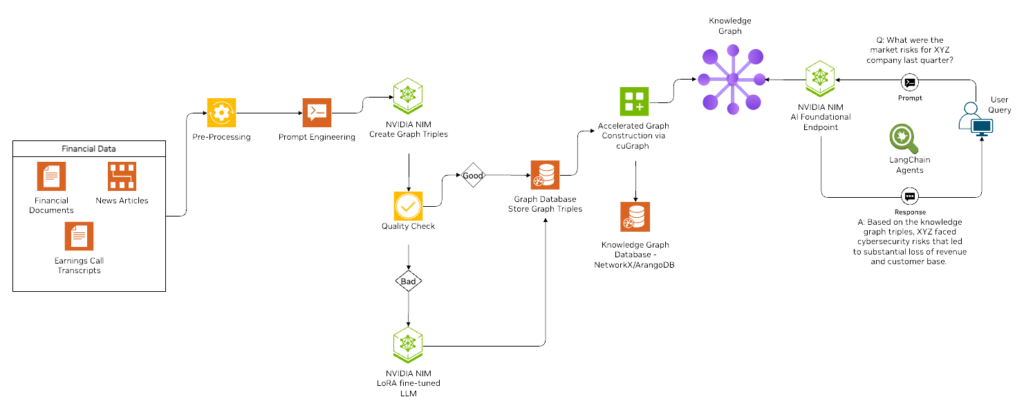
Data collection
For this experiment, we used an academic research dataset from arXiv, containing rich metadata such as article sources, author details, publication dates, and accompanying images. To facilitate replication, we made the open-source code available on GitHub, including scripts for downloading sample research papers in specific domains.
Knowledge graph creation
The process used the Llama-3 70B NIM model with a detailed prompt for extracting entity-relation triples from text chunks. While the initial model performed reasonably well, some outputs were inaccurate.
To address this, we optimized further by fine-tuning a smaller model, Llama3-8B, using the NVIDIA NeMo Framework and Low-Rank Adaptation (LoRA). Mixtral-8x7B generated triplet data for fine-tuning, which improved accuracy, reduced latency, and lower inference costs compared to larger models.
The process parsed the generated triplets into Python lists or dictionaries and indexed them into a graph database. Challenges such as improperly formatted triplets (for example, missing punctuation or brackets) were addressed with the following optimizations:
- Enhanced parsing capabilities: Using the latest LLM models with improved text processing.
- Fine-tuning for triplet extraction: Adding instructions to normalize punctuation and ensure consistency in entity formatting.
- Re-prompting: Correcting malformed outputs by prompting the LLM for refined responses, significantly improving accuracy.
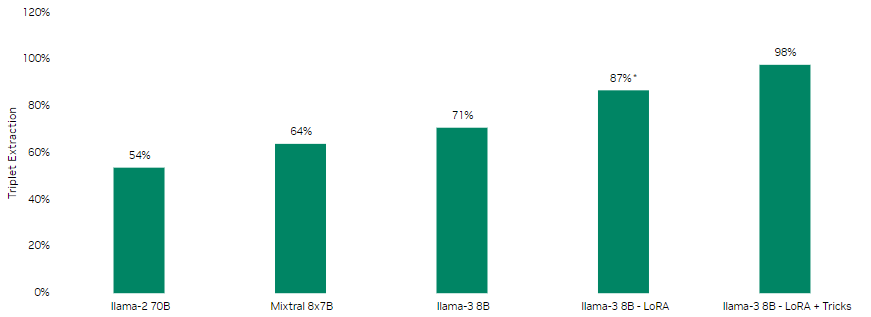
Accuracy comparison
To evaluate the effectiveness of different models and approaches for triplet extraction, we compared their accuracy on a test set of 100 news documents. The results highlight the performance improvements achieved through fine-tuning and optimization.
Consider the following sample paragraph:
”Exxon Mobil, Royal Dutch Shell, Total and their peers are set to cut spending on oil and gas exploration for a fifth year in a row in 2018, according to consultancy Wood Mackenzie (WoodMac), despite a growing urgency to replenish reserves after years of reining back investment.”
Before fine-tuning the Llama-3-8B model, the extracted triplets were incomplete, leading to errors during parsing by the post-processing function.
[('Exxon Mobil', 'ORG', 'Announce', 'Cut Spending', 'EVENT'),
('Exxon Mobil', 'ORG', 'Operate_In', 'Oil and Gas Exploration', 'FIELD'),
('Exxon Mobil', 'ORG', 'Control', 'Oil and Gas Exploration', 'FIELD'),
('Royal Dutch Shell', 'ORG', 'Announce', 'Cut Spending', 'EVENT'),
('Royal Dutch Shell', 'ORG', 'Operate_In', 'Oil and Gas Exploration', 'FIELD')]'
After fine-tuning, the model exhibited a significant improvement in completion rate and accuracy. The refined triplets were more precise and better aligned with the context of the text:
[['Exxon Mobil', 'COMP', 'Cut', 'Spending on oil and gas exploration', 'ACTIVITY'],
['Royal Dutch Shell', 'COMP', 'Cut', 'Spending on oil and gas exploration', 'ACTIVITY'],
['Total', 'COMP', 'Cut', 'Spending on oil and gas exploration', 'ACTIVITY'],
['World’s top oil companies', 'ORG', 'Hesitate', 'Accelerate the search for new resources', 'ACTIVITY']]
Code and schema for triplet extraction
Here’s an /NVIDIA/GenerativeAIExamples code example showcasing the schema and the method used for triplet extraction:
def process_response(triplets_str):
triplets_list = ast.literal_eval(triplets_str)
json_triplets = []
for triplet in triplets_list:
try:
subject, subject_type, relation, object, object_type = triplet
json_triplet = {
"subject": subject,
"subject_type": subject_type,
"relation": relation,
"object": object,
"object_type": object_type
}
json_triplets.append(json_triplet)
except ValueError:
# Skip the malformed triplet and continue with the next one
continue
return json_triplets
def extract_triples(text, llm):
prompt = ChatPromptTemplate.from_messages(
[("system", """Note that the entities should not be generic, numerical, or temporal (like dates or percentages). Entities must be classified into the following categories:
- ORG: Organizations other than government or regulatory bodies
- ORG/GOV: Government bodies (e.g., "United States Government")
- ORG/REG: Regulatory bodies (e.g., "Food and Drug Administration")
- PERSON: Individuals (e.g., "Marie Curie")
- GPE: Geopolitical entities such as countries, cities, etc. (e.g., "Germany")
- INSTITUTION: Academic or research institutions (e.g., "Harvard University")
- PRODUCT: Products or services (e.g., "CRISPR technology")
- EVENT: Specific and Material Events (e.g., "Nobel Prize", "COVID-19 pandemic")
- FIELD: Academic fields or disciplines (e.g., "Quantum Physics")
- METRIC: Research metrics or indicators (e.g., "Impact Factor"), numerical values like "10%" is not a METRIC;
- TOOL: Research tools or methods (e.g., "Gene Sequencing", "Surveys")
- CONCEPT: Abstract ideas or notions or themes (e.g., "Quantum Entanglement", "Climate Change")
The relationships 'r' between these entities must be represented by one of the following relation verbs set: Has, Announce, Operate_In, Introduce, Produce, Control, Participates_In, Impact, Positive_Impact_On, Negative_Impact_On, Relate_To, Is_Member_Of, Invests_In, Raise, Decrease.
Remember to conduct entity disambiguation, consolidating different phrases or acronyms that refer to the same entity (for instance, "MIT" and "Massachusetts Institute of Technology" should be unified as "MIT"). Simplify each entity of the triplet to be less than four words. However, always make sure it is a sensible entity name and not a single letter or NAN value.
From this text, your output Must be in python list of tuple with each tuple made up of ['h', 'type', 'r', 'o', 'type'], each element of the tuple is the string, where the relationship 'r' must be in the given relation verbs set above. Only output the list. As an Example, consider the following news excerpt:
Input :'Apple Inc. is set to introduce the new iPhone 14 in the technology sector this month. The product's release is likely to positively impact Apple's stock value.'
OUTPUT : ```
[('Apple Inc.', 'COMP', 'Introduce', 'iPhone 14', 'PRODUCT'),
('Apple Inc.', 'COMP', 'Operate_In', 'Technology Sector', 'SECTOR'),
('iPhone 14', 'PRODUCT', 'Positive_Impact_On', 'Apple's Stock Value', 'FIN_INSTRUMENT')]
```
The output structure must not be anything apart from above OUTPUT structure. NEVER REPLY WITH any element as NAN. Just leave out the triple if you think it's not worth including or does not have an object. Do not provide ANY additional explanations, if it's not a Python parseable list of tuples, you will be penalized severely. Make the best possible decisions given the context."""), ("user", "{input}")])
chain = prompt | llm | StrOutputParser()
response = chain.invoke({"input": text})
print(response)
return process_response(response)
This structured approach ensured cleaner and more accurate triplet extractions.
Optimizing inference
To scale the workflow for thousands of document chunks, we performed the following optimizations:
- Converted model weights: Transformed NeMo-trained model weights into a TensorRT-LLM checkpoint.
- Optimized inference engines: Used GPU-accelerated inference for faster performance.
- Deployed scalable systems: Used the optimized model checkpoint to enable high-throughput inference, significantly enhancing performance across large datasets.
By integrating advanced LLM optimization techniques and fine-tuning workflows, we achieved efficient and scalable knowledge graph generation, providing a robust foundation for enterprise AI applications.
Accelerating knowledge graphs with NVIDIA cuGraph for scalable AI workflows
NVIDIA has dedicated years to advancing AI workflows on GPUs, especially in the areas like graph neural networks (GNNs) and complex data representations. Building on this expertise, the NVIDIA RAPIDS data science team developed cuGraph, a GPU-accelerated framework for graph analytics. cuGraph significantly enhances the efficiency of RAG systems by enabling scalable and high-speed graph operations.
In knowledge graph retrieval-augmented generation (KRAG), knowledge graphs are queried to retrieve relevant information that enhances the context for language models during text generation. cuGraph high-performance algorithms such as shortest path, PageRank, and community detection quickly identify and rank relevant nodes and edges within large-scale knowledge graphs. By doing so, cuGraph ensures faster and more accurate retrieval of contextually relevant information, improving the quality of AI-generated outputs.
What makes cuGraph particularly powerful is its seamless integration with widely used open-source tools like NetworkX, RAPIDS cuDF, and cuML. This integration enables you to accelerate graph workflows with minimal code changes, enabling quick adoption and immediate performance gains.
In our open-source implementation, we used cuGraph for loading and managing graph representations through NetworkX, achieving scalability across billions of nodes and edges on multi-GPU systems. cuGraph also powers efficient graph querying and multi-hop searches, making it an indispensable tool for handling large and complex knowledge graphs.
Insights into VectorRAG, GraphRAG, and HybridRAG
We conducted a comprehensive comparative analysis of three RAG techniques: VectorRAG, GraphRAG, and HybridRAG. We used the nemotron-340b reward model to evaluate the quality of their outputs.
Evaluation metrics
The evaluation focused on the following key metrics, scored on scale of 0 to 4 (higher is better):
- Helpfulness: Measures how effectively the response addresses the prompt.
- Correctness: Assesses the inclusion of all pertinent facts without inaccuracies.
- Coherence: Evaluates the consistency and clarity of expression in the response.
- Complexity: Determines the intellectual depth required to generate the response (for example, whether it demands deep domain expertise or can be produced with basic language competency).
- Verbosity: Analyzes the level of detail provided relative to the requirements of the prompt.
For more information, see the model cards.
Dataset and experimental setup
The dataset used for this study contains research papers gathered from arXiv. Ground-truth (GT) question-answer pairs are synthetically generated using the nemotron-340b synthetic data generation model.
Results summary with key insights
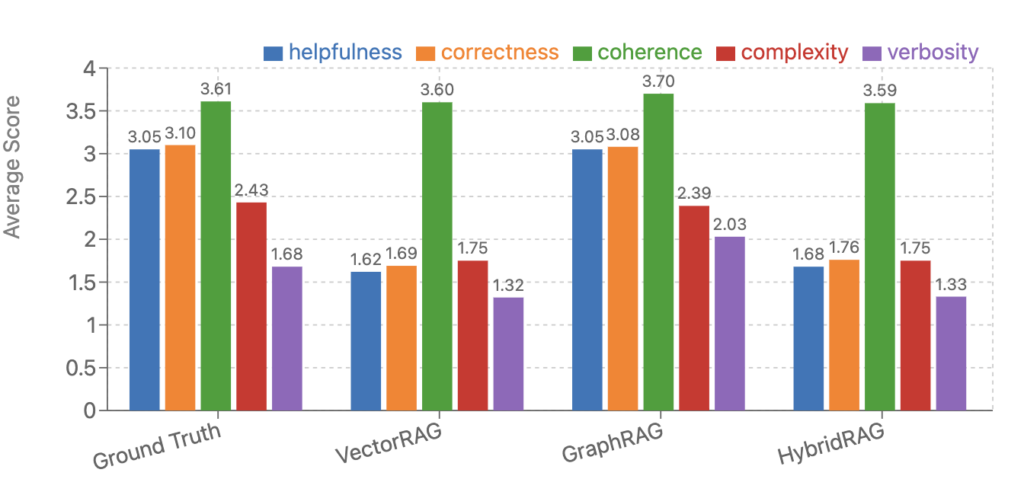
Note: HybridRAG underperforms compared to pure GraphRAG in this instance because the dataset was synthetically designed for multihop reasoning to highlight GraphRAG’s strengths. For real-world data, HybridRAG would likely deliver the best results in most scenarios.”
The analyses revealed significant performance differences across the techniques:
- Correctness: GraphRAG excelled in correctness, providing responses that are highly accurate and stayed true to the source data.
- Overall performance: GraphRAG demonstrated superior performance across all metrics, delivering responses that were accurate, coherent, and contextually aligned. Its strength lies in using relational context for richer information retrieval, making it particularly effective for datasets requiring a high level of accuracy.
- Potential of HybridRAG: Depending on the dataset and context injection, HybridRAG has shown potential to outperform traditional VectorRAG on nearly every metric. Its graph-based retrieval capabilities enable the improved handling of complex data relationships, although this may result in a slight trade-off in coherence.
- HybridRAG as a balanced approach: HybridRAG emerges as a balanced and effective technique, seamlessly combining the flexibility of semantic VectorRAG with advanced multi-hop reasoning and global context summarization. This makes it particularly well-suited for regulated domains such as finance and healthcare, where strong grounding of responses is critical. Its approach enables accurate and efficient information extraction, meeting the stringent demands of these industries.
The integration of graph-retrieval techniques has the potential to redefine how RAG methods handle complex, large-scale datasets, making them ideal for applications requiring multi-hop reasoning across relationships, high level of accuracy and deep contextual understanding.
Exploring the future of LLM-powered knowledge graphs
In this post, we examined how integrating LLMs with knowledge graphs enhances AI-driven information retrieval, excelling in areas like multi-hop reasoning and advanced query responses. Techniques such as VectorRAG, GraphRAG, and HybridRAG show remarkable potential, but several challenges remain as we push the boundaries of this technology.
Here are some key challenges:
- Dynamic information updates: Incorporating real-time data into knowledge graphs, adding new nodes and relationships, and ensuring relevance during large-scale updates.
- Scalability: Managing knowledge graphs that grow to billions of nodes and edges while maintaining efficiency and performance.
- Triplet extraction refinement: Improving the precision of entity-relation extraction to reduce errors and inconsistencies.
- System evaluation: Developing robust domain-specific metrics and benchmarks for evaluating graph-based retrieval systems to ensure consistency, accuracy, and relevance.
Some future directions could include any of the following:
- Dynamic knowledge graphs: Refining techniques to scale dynamic updates seamlessly, enabling graphs to evolve with the latest data.
- Expert agent integration: Exploring how knowledge graph retrieval can function as an expert system, offering specialized insights for domain-specific applications.
- Graph embeddings: Developing semantic representations of embeddings for entire knowledge graphs to unlock new capabilities in graph analytics and information retrieval.
To dive into these innovations, explore the NVIDIA NeMo Framework, NVIDIA NIM microservices, and cuGraph for GPU-accelerated knowledge graph creation and optimization.
To replicate the workflows discussed in the post and other open-source examples, see the /NVIDIA/GenerativeAIExamples GitHub repo. These tools empower you to scale your systems efficiently, whether you’re building dynamic knowledge graphs, fine-tuning LLMs, or optimizing inference pipelines.
Push the boundaries of AI innovation with NVIDIA cutting-edge technologies today!