

{kind=link}
Microsoft has open-sourced Phi-4, its compact language model, to the public by releasing its full weights on Hugging Face under an MIT License.
Phi-4, first introduced in December 2024 through Microsoft’s Azure AI Foundry platform, was initially available only to researchers under a controlled license. With the open-source release, Microsoft provides researchers and developers worldwide with the tools to customize, deploy, and commercialize the compact yet high-performing model.
Phi-4: A Compact Model with Outsized Results
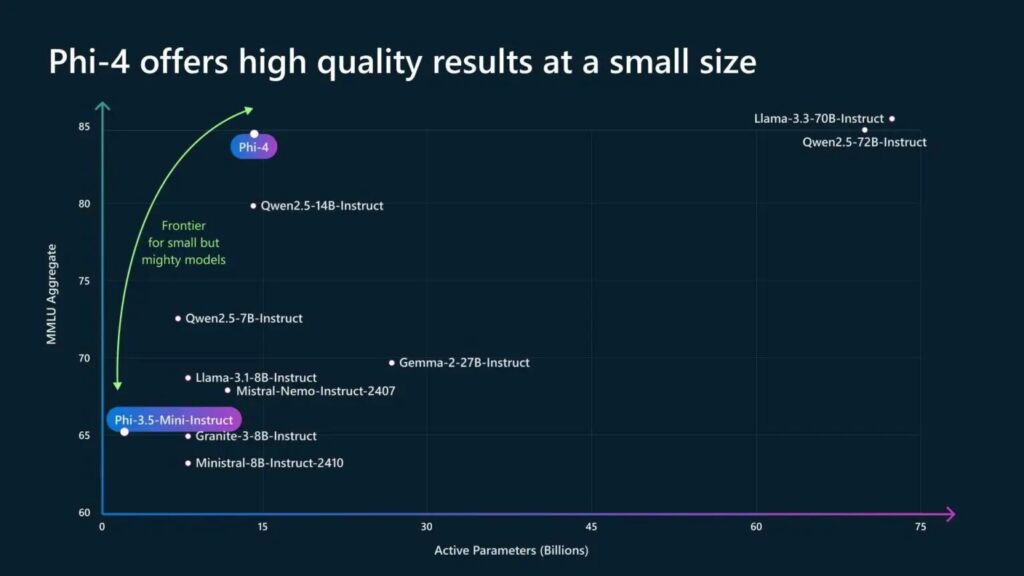
Phi-4 represents a departure from traditional AI development, which has often prioritized scale as the primary metric for performance. At just 14 billion parameters, Phi-4 delivers results that rival and even surpass larger counterparts, such as Google’s Gemini Pro 1.5 and OpenAI’s GPT-4o.
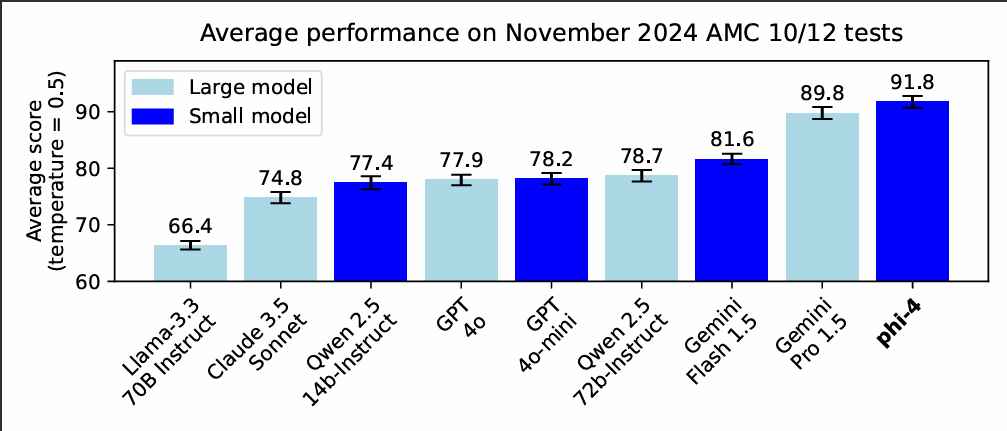
In recent benchmarks, Phi-4 scored an impressive 91.8 on the American Mathematics Competition (AMC 12), outperforming Gemini Pro 1.5’s score of 89.8 and GPT-4o’s 77.9.
Microsoft showcased Phi-4’s mathematical reasoning capabilities through a combinatorics problem, where the model accurately calculated 431 distinct permutations for a hypothetical race involving five snails.
This level of precision highlights its potential for domains requiring logical and mathematical rigor, such as finance, engineering, and scientific research.
Microsoft explained its objectives for Phi-4 in its official documentation: “Phi-4 continues to push the frontier of size versus quality,” a sentiment echoed by researchers who have compared its performance to models with five times the number of parameters.
Training Methodology and Synthetic Data
The foundation of Phi-4’s success lies in its training approach. Microsoft leveraged synthetic datasets comprising textbook-style content, emphasizing mathematical reasoning, programming, and common-sense logic. These datasets, totaling 9.8 trillion tokens, were supplemented by curated public documents, academic texts, and multilingual data.
“Rather than serving as a cheap substitute for organic data, synthetic data offers direct advantages,” Microsoft noted in its technical report, highlighting the control and adaptability it affords during model training. This approach also reduced reliance on web-scraped content, often criticized for quality inconsistencies.
To enhance the model’s reasoning and alignment, Microsoft applied advanced post-training techniques such as supervised fine-tuning and direct preference optimization. These methodologies refined Phi-4’s ability to distinguish between high-quality and low-quality outputs, further boosting its accuracy in domain-specific applications.
Open-Source Availability
The decision to release Phi-4 as open-source reflects Microsoft’s broader strategy to democratize AI tools. Developers can now access the model on Hugging Face, where its full weights are available under an MIT License. Shital Shah, a principal engineer at Microsoft, announced the release on X (formerly Twitter), writing, “A lot of folks had been asking us for weight release… Well, wait no more.”
We have been completely amazed by the response to phi-4 release. A lot of folks had been asking us for weight release. Few even uploaded bootlegged phi-4 weights on HuggingFace😬.
Well, wait no more. We are releasing today official phi-4 model on HuggingFace!
With MIT licence!! pic.twitter.com/rcugWBPU4r
— Shital Shah (@sytelus) January 8, 2025
The open-source release enables developers to customize Phi-4 for specific applications without the computational overhead typically associated with larger models. Its dense, decoder-only architecture, a variant of the transformer model, minimizes resource requirements, making it accessible even to organizations with limited infrastructure.
Ethical Considerations and Industry Impacts
Microsoft’s rollout of Phi-4 highlights its commitment to responsible AI deployment. The Azure AI Foundry platform, which initially hosted Phi-4, incorporates safeguards such as content filtering and adversarial testing. These measures are designed to mitigate risks like bias, misinformation, and harmful content generation.
By releasing Phi-4 under an open-source license, Microsoft also addresses the growing demand for transparency in AI development. The move aligns with industry trends seen in releases like Meta’s Llama 3.2 and Google’s Gemma series, though Phi-4’s standout performance in benchmarks sets a new standard for compact models.
Phi-4 challenges the assumption that bigger models are inherently better. Its compact design not only reduces computational and energy costs but also broadens access to advanced AI capabilities. This efficiency is particularly valuable for mid-sized organizations and researchers who lack the resources to deploy massive models.
As AI continues to evolve, Phi-4 offers a glimpse into a future where smaller, smarter models can meet the demands of specialized tasks without compromising performance.
Last Updated on January 10, 2025 12:28 pm CET