Chinese AI startup Z.ai is escalating the nation’s fierce AI price war with its new GLM-4.5 models. The company, formerly Zhipu, announced the open-source release on Monday. It positions the new models to be cheaper than those from key rival DeepSeek.
Built for complex “agentic” tasks, the release targets the industry’s shift toward autonomous AI. These systems can execute multi-step instructions. This move intensifies competition in China’s tech sector, where firms now battle on both power and price.
The launch also occurs as Z.ai operates under U.S. sanctions, adding a geopolitical layer to the rivalry. The models are available via the Z.ai platform, an API, and as open-weights on Hugging Face.
Under the Hood: An Agentic Model Built for Efficiency
Z.ai’s new GLM-4.5 family is engineered for the next wave of AI applications, moving beyond simple instruction-following to embrace a more sophisticated “agentic” framework. According to the company’s technical blog post, the models are designed to unify reasoning, coding, and agentic tool use, allowing them to autonomously break down complex requests, form a plan, and execute tasks without continuous human guidance. This approach aims to satisfy the increasingly complicated requirements of emerging agentic applications.
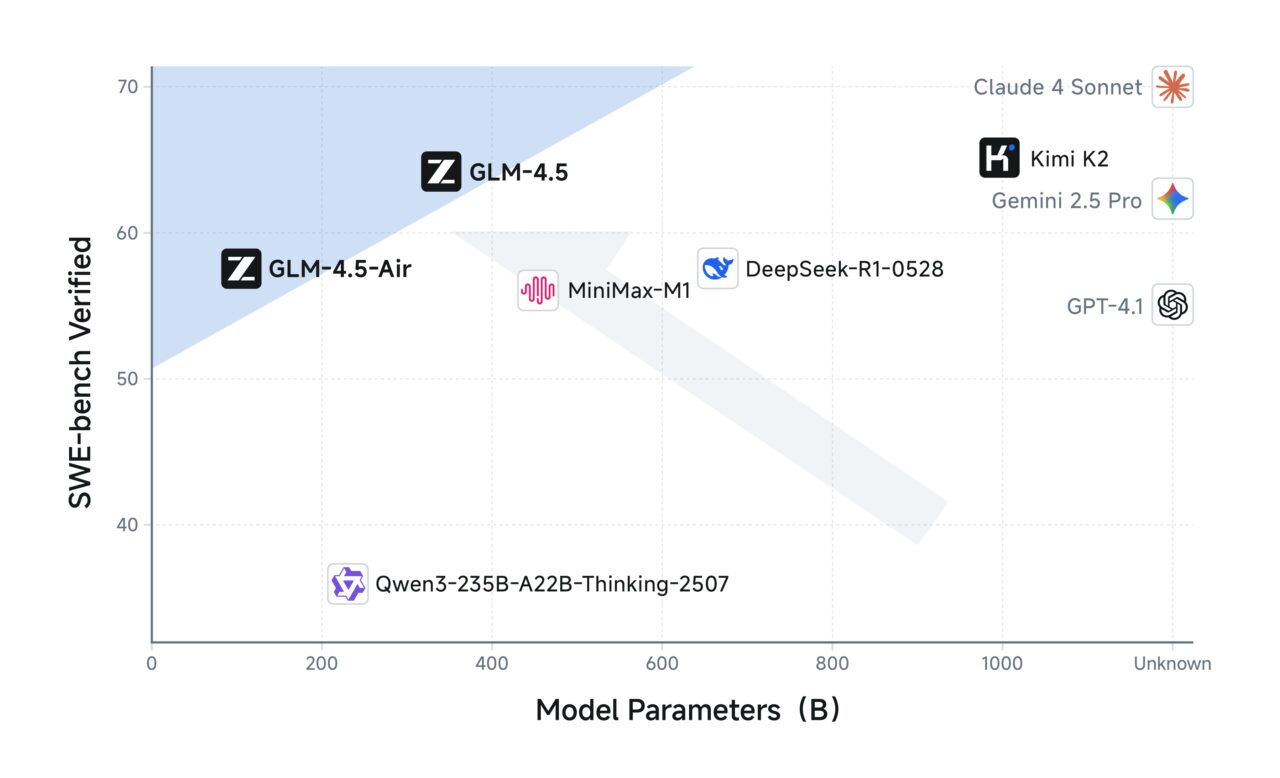
The flagship GLM-4.5 is a powerful Mixture-of-Experts (MoE) model, a design choice that enhances computational efficiency. While it contains a massive 355 billion total parameters, it only activates a 32-billion-parameter subset for any given task. Z.ai also released a smaller GLM-4.5-Air variant with 106 billion total parameters and 12 billion active ones for even greater efficiency. In a strategic departure from rivals like DeepSeek-V3 and Kimi K2, Z.ai prioritized a “deeper, not wider” architecture, increasing the number of layers to enhance the model’s core reasoning capacity.
Underpinning this architecture are several key technical innovations. The model employs Grouped-Query Attention and a higher number of attention heads to improve performance on reasoning benchmarks. To ensure stability during its massive training run, which involved a 15-trillion-token general corpus followed by a 7-trillion-token code and reasoning corpus, the team utilized a Muon optimizer and QK-Norm to stabilize attention logits. The model also features native function calling and a 128k context length, both critical for enabling its advanced agentic abilities.
Remarkably, Z.ai claims the flagship model can operate on just eight of Nvidia’s H20 chips. This hardware is the export-controlled version designed for the Chinese market, and the model’s efficiency underscores a strategic focus on delivering high performance within significant hardware constraints. This combination of advanced architecture, massive-scale training, and hardware optimization positions GLM-4.5 as a formidable new entry in the global AI landscape.
Performance
According to comprehensive benchmarks published by Z.ai, the new GLM-4.5 model establishes itself as a top-tier contender, ranking third overall against a field of leading proprietary and open-source models from OpenAI, Anthropic, and Google. The smaller GLM-4.5-Air also performs strongly, securing the sixth position. This data suggests that Z.ai has successfully developed a model that competes at the frontier of AI capability, challenging the established hierarchy.
In tests designed to measure its agentic abilities, GLM-4.5 demonstrates impressive results. On the -bench and Berkeley Function Calling Leaderboard (BFCL-v3), its performance matches that of Claude 4 Sonnet. The model also excels at complex web browsing tasks, outperforming Claude-4-Opus on the challenging BrowseComp benchmark. Its “thinking” mode proves effective in advanced reasoning, achieving a score of 91.0 on the AIME24 math competition test and 79.1 on the GPQA graduate-level question-answering benchmark.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | Claude 4 Opus | Gemini 2.5 Pro | DeepSeek-R1-0528 | Qwen3-235B-Thinking 2507 | Grok 4 |
|---|---|---|---|---|---|---|---|---|
| MMLU Pro | 84.6 | 81.4 | 85.3 | 87.3 | 86.2 | 84.9 | 84.5 | 86.6 |
| AIME24 | 91.0 | 89.4 | 90.3 | 75.7 | 88.7 | 89.3 | 94.1 | 94.3 |
| MATH 500 | 98.2 | 98.1 | 99.2 | 98.2 | 96.7 | 98.3 | 98.0 | 99.0 |
| SciCode | 41.7 | 37.3 | 41.0 | 39.8 | 42.8 | 40.3 | 42.9 | 45.7 |
| GPQA | 79.1 | 75.0 | 82.7 | 79.6 | 84.4 | 81.3 | 81.1 | 87.7 |
| HLE | 14.4 | 10.6 | 20.0 | 11.7 | 21.1 | 14.9 | 15.8 | 23.9 |
| LiveCodeBench (2407-2501) | 72.9 | 70.7 | 78.4 | 63.6 | 80.1 | 77.0 | 78.2 | 81.9 |
| AA-Index (Estimated) | 67.7 | 64.8 | 70.0 | 64.4 | 70.5 | 68.3 | 69.4 | 73.2 |
The model’s coding capabilities are equally robust. In a direct, multi-round human evaluation using a standardized coding framework, GLM-4.5 achieved a 53.9% win rate against Moonshot’s Kimi K2 and dominated Alibaba’s Qwen3-Coder with an 80.8% success rate. Z.ai also reports a tool-calling success rate of 90.6%, the highest among its peers, demonstrating superior reliability for agentic coding tasks. The full trajectories for these tests have been made publicly available for community review.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | DeepSeek-R1-0528 | Kimi K2 |
|---|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified1 | 64.2 | 57.6 | 69.1 | 48.6 | 67.8 | 70.4 | 49.0 | 41.4 | 65.4 |
| Terminal-Bench2 | 37.5 | 30 | 30.2 | 30.3 | 43.2 | 35.5 | 25.3 | 17.5 | 25.0 |
This strong performance is paired with remarkable efficiency. A Pareto Frontier analysis conducted by Z.ai shows that both GLM-4.5 and GLM-4.5-Air sit on the optimal trade-off boundary for performance versus model scale. This indicates that the models achieve their top-tier results without the computational overhead of similarly powerful competitors, reinforcing the company’s strategic focus on delivering both high performance and cost-effectiveness.

Escalating China’s Fierce AI Price War
The release is a direct shot at domestic competitors, most notably DeepSeek. Z.ai is explicitly undercutting its rival on price. The company will charge 11 cents per million input tokens for GLM-4.5, compared to the 14 cents DeepSeek charges for its R1 model.
This aggressive pricing continues a trend that has roiled the AI sector. DeepSeek itself gained prominence by offering services at a fraction of the cost of OpenAI’s models. Now, Z.ai is intensifying this price war, forcing companies to compete on efficiency, not just raw power.
According to Z.ai’s own benchmarks, GLM-4.5 competes favorably with top-tier models from OpenAI, Google, and Anthropic on a range of reasoning, coding, and agentic tests.
A New Contender in a Geopolitical Minefield
Z.ai’s technical advances are set against a backdrop of intense geopolitical pressure. The company, under its former name Zhipu, was placed on a U.S. entity list, which restricts its ability to do business with American firms.
OpenAI has also previously flagged the startup’s rapid progress. The U.S. government has expressed deep concerns over Chinese AI development. A recent House Committee report branded rival DeepSeek a security threat, with Chairman John Moolenaar stating, “this report makes it clear: DeepSeek isn’t just another AI app — it’s a weapon in the Chinese Communist Party’s arsenal…”
This environment forces Chinese firms to innovate under constraints. The reliance on Nvidia’s H20 chips is a direct consequence of U.S. export controls aimed at slowing China’s AI ambitions. Yet, Z.ai CEO Zhang Peng told CNBC the company has enough computing power, stating, “the company doesn’t need to buy more of the chips as it has enough computing power for now.”
The timing is also critical. Z.ai’s launch comes as DeepSeek’s momentum has reportedly stalled. The company’s highly anticipated R2 model has been indefinitely delayed, partly due to the very hardware shortages Z.ai has engineered its models to navigate.
The Global Race for Agentic Supremacy
The focus on “agentic AI” places Z.ai at the forefront of a fundamental industry shift. The goal is moving beyond chatbots that answer questions to autonomous agents that complete tasks. This trend is already being validated in the corporate world.
Investment bank Goldman Sachs, for example, is piloting AI agents to create a “hybrid workforce.” Tech chief Marco Argenti explained the vision, saying, “it’s really about people and AIs working side by side. Engineers are going to be expected to have the ability to really describe problems in a coherent way…” This reflects a future where humans supervise AI, not just use it as a tool.
Z.ai is not alone in this race. Alibaba recently released its Qwen3-Coder and Moonshot AI launched its Kimi K2 model, both targeting agentic capabilities. Even OpenAI’s Sam Altman acknowledged the competitive pressure from China, promising earlier this year, “we will obviously deliver much better models and also pull up some releases.”
By open-sourcing GLM-4.5, Z.ai is making a strategic play for developer adoption. This approach invites global collaboration even as geopolitical tensions rise.