Comprehensive A100 GPU Price Analysis for Cost-Effective AI Infrastructure
Table of Contents
The A100 GPU has been a cornerstone of artificial intelligence (AI) and high-performance computing (HPC) for several years, driving innovation in data centers and cloud environments globally. Launched by NVIDIA in 2020 and built on the Ampere architecture, the A100 transformed the economics of accelerated computing, offering unparalleled performance for complex workloads ranging from large language model (LLM) training to intricate data analytics and scientific simulations. Despite the advent of newer generations like the H100 and Blackwell, the A100 continues to hold significant relevance in 2026, largely due to its stabilized pricing, robust ecosystem, and proven capabilities. This comprehensive analysis delves into the intricate pricing dynamics of the A100 GPU, examining its cost components, market availability, and strategic value for AI servers and data centers in the current technological landscape.
Introduction: The NVIDIA A100 in the AI Landscape
Since its introduction, the NVIDIA A100 Tensor Core GPU has been lauded as the flagship product of NVIDIA’s data center platform, designed to deliver unprecedented acceleration for AI, data analytics, and HPC tasks. Its ability to efficiently scale up to thousands of GPUs or be partitioned into seven isolated GPU instances using Multi-Instance GPU (MIG) technology has made it incredibly versatile for workloads of all sizes. The A100’s third-generation Tensor Core technology significantly improved deep learning training and inference performance, offering up to 20 times the Tensor FLOPS and TOPS compared to its predecessors. This foundational strength ensures that the A100 remains a critical component for many organizations, particularly those focused on large-scale inference and mid-sized training workloads where cost-effectiveness is paramount. The enduring utility of the A100 is a testament to its balanced performance, broad software support, and consistent supply, making understanding its current price analysis crucial for strategic IT investment decisions.
NVIDIA A100: Technical Overview and Key Specifications
The NVIDIA A100 GPU is engineered on the NVIDIA Ampere GPU architecture, featuring over 54 billion transistors built on a 7-nanometer process. It boasts core specifications that underpin its exceptional performance: 6912 shading units, 432 Tensor Cores (third-generation), and 108 Streaming Multiprocessors (SMs). A critical differentiator for the A100 is its high-bandwidth memory (HBM2e), available in 40GB and 80GB configurations. The 40GB variant offers a memory bandwidth of 1.6 TB/s, while the 80GB model pushes this to over 2 TB/s, which is vital for handling large datasets and memory-intensive computational tasks efficiently.
Further enhancing its capabilities, the A100 incorporates next-generation NVLink technology, providing up to 600 GB/s throughput when combined with NVIDIA NVSwitch, enabling seamless high-speed communication between multiple GPUs in a server. The Multi-Instance GPU (MIG) feature allows a single A100 to be divided into up to seven hardware-isolated instances, maximizing GPU utilization for diverse workloads, from small development tasks to multi-tenant inference environments. These features collectively make the A100 a highly adaptable and powerful accelerator for a wide array of AI and HPC applications, maintaining its relevance even as newer architectures emerge.
Factors Influencing A100 Pricing
The price of an NVIDIA A100 GPU is influenced by several interconnected factors, creating a dynamic market environment for AI servers and data centers. These factors include memory capacity, form factor, market demand, supply chain dynamics, and vendor-specific pricing strategies.
- Memory Capacity: The A100 is primarily available in 40GB and 80GB HBM2e configurations. The 80GB variant typically commands a higher price due to its doubled memory and faster bandwidth, making it more suitable for larger models, multi-model serving, and memory-bound tasks. For instance, fine-tuning large language models (LLMs) with 70 billion parameters or more often necessitates the 80GB version.
- Form Factor: The A100 comes in two main form factors: PCIe and SXM. PCIe cards are standard add-in cards compatible with most servers, offering ease of integration. SXM modules, on the other hand, are designed for direct socketing onto motherboards in NVIDIA DGX systems and specialized OEM servers, enabling higher bandwidth connections (up to 600 GB/s via NVLink) and superior multi-GPU scaling. SXM versions are generally more expensive due to their enhanced performance capabilities and specialized integration requirements.
- Market Demand: The escalating global demand for AI and HPC, particularly for training and deploying large language models, has a direct impact on GPU prices. While newer GPUs like the H100 and B200 are now considered frontier hardware, the A100 continues to see strong demand for established production workloads and inference tasks where it offers an optimal balance of cost and performance.
- Supply Chain Factors: Global chip shortages, though somewhat eased, can still affect the supply and, consequently, the price of A100 GPUs. However, as NVIDIA shifts focus to newer generations, the A100’s supply has stabilized, making it widely available through existing inventory and cloud providers.
- Vendor and Reseller Pricing: Prices can vary significantly based on the vendor, reseller, and geographical region. Some resellers may offer discounts or bundled deals, while others might charge a premium. Cloud providers also have distinct pricing models, offering on-demand, reserved, and spot instances that influence the effective hourly cost.
Understanding these factors is crucial for organizations aiming to make informed purchasing or rental decisions for A100 GPUs.
A100 Pricing Models: Purchase vs. Cloud Rental
The decision between purchasing A100 GPUs for on-premise deployment and renting them from cloud providers is a strategic one, heavily influenced by budget, utilization patterns, and operational needs. Both models present distinct financial implications and benefits.
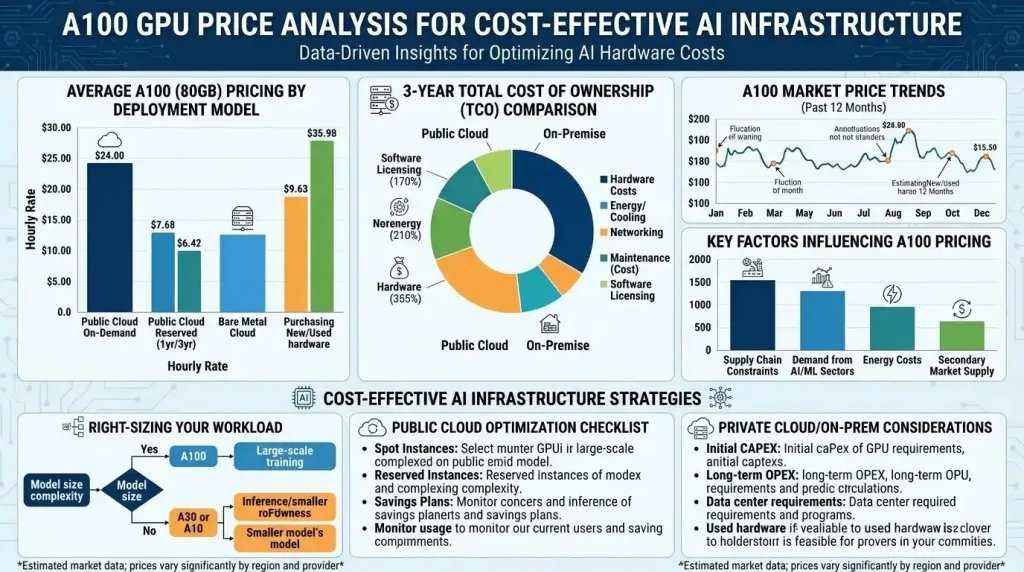
For direct purchases, the cost of a new NVIDIA A100 GPU varies significantly based on its configuration. As of early 2026, a new A100 40GB PCIe model typically ranges from $10,000 to $12,000. The A100 80GB variant, whether PCIe or SXM, is priced higher, generally between $15,000 and $17,000. The SXM version, due to its specialized interconnects and higher performance in multi-GPU setups, often sits at the upper end of this range, with some sources citing prices up to $18,000-$20,000 for the 80GB SXM model. Complete systems like the NVIDIA DGX A100, which includes eight A100 GPUs with NVLink, networking, and NVMe storage, can exceed $150,000 or even $200,000 new, excluding ongoing power and maintenance costs.
The secondary market for A100 GPUs has become increasingly active as enterprises upgrade to newer hardware like H100s and H200s. This influx has led to a noticeable drop in prices for used units, making them an attractive option for budget-conscious organizations. Refurbished A100 40GB units can be found for as low as $7,800, while used A100 80GB PCIe cards are listed around $18,900. Some reports even indicate used 40GB PCIe units as low as $2,000–$3,500, and new 80GB SXM4 modules between $7,500–$12,000, depending on vendor and integration, although buyers should be wary of gray-market imports or untested inventory.
Cloud GPU rental, on the other hand, offers flexibility and reduces upfront capital expenditure. Major cloud providers such as AWS, Google Cloud Platform (GCP), and Azure, alongside specialized GPU cloud platforms like RunPod, Jarvislabs, Lambda Labs, and Thunder Compute, offer A100 instances with various pricing models.
Cloud pricing for A100 GPUs varies significantly by provider, configuration, and region. As of early to mid-2026:
- On-demand rates for A100 80GB instances generally start around $1.39 per hour on specialized providers and can go up to $5 per hour on hyperscalers like GCP and AWS.
- Some providers, like Jarvislabs and Thunder Compute, offer highly competitive rates, with A100 80GB instances available for as low as $1.49/hour and even $0.78/hour respectively, often with per-minute or per-second billing to avoid paying for idle time.
- Spot pricing, which utilizes unused capacity, can further reduce costs, with A100 80GB instances sometimes dipping below $1/hour.
- For A100 40GB GPUs, on-demand prices range from approximately $3.67/hour on GCP to $4.10/hour on AWS. Some providers list A100 PCIe 40GB at around $1.19/hour.
The choice between buying and renting hinges on factors like utilization rate. For continuous 24/7 operation, owning an A100 server might become more cost-effective after approximately 12 months, considering depreciation, power, and cooling. However, for intermittent workloads, experimentation, or when rapid scalability is needed without significant upfront investment, cloud rental remains the more practical and cost-efficient solution. The availability of per-minute billing and persistent storage on many cloud platforms further enhances their appeal for dynamic AI workloads.
Cost-Benefit Analysis for AI Servers and Data Centers

The NVIDIA A100 GPU represents a significant investment for AI servers and data centers, necessitating a thorough cost-benefit analysis to justify its deployment. Its value proposition extends beyond raw performance, encompassing efficiency, versatility, and the total cost of ownership (TCO).
Benefits of A100 in AI Servers and Data Centers:
- Exceptional Performance for Diverse Workloads: The A100’s Ampere architecture and Tensor Cores provide robust acceleration for a wide range of AI tasks, including deep learning training, inference, and high-performance data analytics. It offers substantial speedups compared to previous generations, enabling faster model development and deployment.
- Memory Capacity and Bandwidth: With up to 80GB of HBM2e memory and bandwidth exceeding 2TB/s, the A100 can handle massive datasets and complex models that are common in modern AI applications. This is particularly beneficial for large language models and multi-model serving, where memory capacity is a critical bottleneck.
- Multi-Instance GPU (MIG): The ability to partition a single A100 into up to seven isolated GPU instances significantly enhances utilization, allowing data centers to efficiently run multiple smaller workloads concurrently on a single physical GPU. This maximizes hardware investment and reduces idle capacity.
- Mature Ecosystem and Software Support: The A100 benefits from a mature software ecosystem, including NVIDIA CUDA, TensorRT, and optimized AI frameworks. This ensures broad compatibility, robust development tools, and a wealth of existing expertise, accelerating development and deployment.
- Cost-Effectiveness for Specific Use Cases: While newer GPUs offer higher peak performance, the A100 provides an excellent price-to-performance ratio for many workloads, especially for large-scale inference and medium-sized training jobs. Its stabilized pricing in 2026 makes it a compelling value leader compared to the more expensive H100, which can be 40-60% pricier per hour.
Costs and Considerations:
- Upfront Capital Expenditure: Purchasing A100 GPUs, especially in bulk for a data center, represents a substantial capital outlay. A single A100 can cost between $7,000 and $20,000, with an 8-GPU DGX A100 system ranging from $150,000 to $200,000.
- Operational Costs: AI servers equipped with A100s consume significant power and generate considerable heat, leading to high energy and cooling costs. AI servers can consume up to 10 times more power than traditional cloud servers.
- Infrastructure Requirements: On-premise deployment necessitates robust data center infrastructure, including specialized cooling systems, high-speed networking (e.g., NVLink, InfiniBand), and skilled IT staff for maintenance and management.
- Depreciation and Obsolescence: The rapid pace of GPU innovation means that hardware can depreciate quickly. While the A100 remains relevant, newer generations will eventually offer superior performance per watt, potentially making older hardware less economically viable over time.
| A100 Configuration | New Purchase Price (Approx. 2026) | Used/Refurbished Price (Approx. 2026) | Cloud Rental Rate (On-Demand, per hour, Approx. 2026) |
|---|---|---|---|
| A100 40GB PCIe | $10,000 – $12,000 | $2,000 – $8,000 | $1.19 – $4.10 (Varies by provider) |
| A100 80GB PCIe | $15,000 – $17,000 | $8,000 – $12,000 | $1.39 – $5.00 (Varies by provider) |
| A100 80GB SXM | $15,000 – $20,000 | $7,500 – $12,000 | $1.39 – $5.00 (Varies by provider) |
| DGX A100 (8x GPUs) | $150,000 – $200,000 | $80,000 – $120,000 | Equivalent cost by renting 8 A100 instances |
A100 vs. Alternatives and the Future Outlook
In the rapidly evolving landscape of AI accelerators, the NVIDIA A100, while still a powerful and relevant GPU, faces competition from both newer NVIDIA architectures and alternative solutions. Understanding these comparisons is crucial for making informed investment decisions in 2026 and beyond.
NVIDIA’s Newer Generations: H100 and Blackwell
The immediate successor to the A100 is the NVIDIA H100, based on the Hopper architecture, which was released in 2022. The H100 significantly surpasses the A100 in raw performance, especially for large language model training, offering up to 6 times faster AI performance through enhanced Transformer Engine and FP8 precision support. It features fourth-generation Tensor Cores and a dedicated Transformer Engine, with some configurations boasting 80GB HBM3 memory at 3.35TB/s bandwidth. An H100 GPU can cost significantly more, ranging from $27,000 to $40,000 per unit. For cloud rentals, H100 rates are typically 40-60% higher than A100s, with on-demand prices around $2.99 to $8 per hour.
Further pushing the boundaries is the Blackwell architecture, including GPUs like the B200 and GB200, which are expected to offer even more substantial performance and energy efficiency gains. Blackwell GPUs are specifically tuned for training large language models and handling long-context tasks, with the B200 potentially costing $30,000 to $50,000 per unit. The rapid release cadence of these new generations means that older hardware, while still functional, may become economically obsolete faster due to superior performance-per-watt ratios.
Consumer-Grade GPUs (e.g., RTX 4090)
For smaller teams, researchers, or specific use cases, consumer-grade GPUs like the NVIDIA RTX 4090 (Ada Lovelace architecture) can serve as a more budget-friendly alternative. The RTX 4090, priced around $1,600, offers impressive inference performance for models up to 7B parameters and can be a cost-effective option for local AI workloads or experimentation. However, it relies on GDDR6X memory rather than HBM, making it less suitable for large-scale LLM training or high-density enterprise inference clusters. Two RTX 4090s can, in some scenarios, deliver performance comparable to a single A100 for small-to-medium models, particularly in terms of latency and throughput.
Other Data Center Alternatives (e.g., AMD MI300X, NVIDIA A30)
While NVIDIA dominates the AI GPU market, alternatives from AMD, such as the MI300X, are emerging as competitive options, with pricing around $10,000 to $15,000 and offering substantial memory. Within NVIDIA’s own data center lineup, the A30 GPU is a more cost-effective option specifically optimized for inference of small-to-medium models, with a lower power consumption and hourly cloud rental cost (around €0.60/hour compared to €2.15/hour for an A100 80GB).
Future Outlook
The A100’s future in 2026 and beyond appears to be as a stable, cost-optimized workhorse for established production AI workloads, particularly for inference, fine-tuning, and medium-scale training where peak H100/Blackwell performance isn’t strictly necessary. Its deep availability across cloud providers and a growing secondary market will continue to offer attractive options for organizations balancing cost and performance. However, the increasing demand for massive computational power for frontier AI models will undeniably drive the adoption of H100, H200, and Blackwell GPUs in hyperscale data centers. This creates a stratified market where the A100 remains a viable and highly efficient choice for a significant segment of AI and HPC applications, while newer generations cater to the absolute cutting edge.
Total Cost of Ownership (TCO) Considerations
When evaluating the A100 GPU for AI servers and data centers, a crucial metric is the Total Cost of Ownership (TCO). TCO extends beyond the initial purchase price to include all direct and indirect costs associated with the GPU’s lifecycle. A comprehensive TCO analysis helps organizations make economically sound decisions, especially when comparing on-premise deployments with cloud-based solutions.
Key components of A100 TCO include:
- Hardware Acquisition Cost: As detailed earlier, this is the upfront cost of the A100 GPUs themselves, along with associated server components like CPUs, RAM, storage, and networking (e.g., NVLink, InfiniBand). For an 8x A100 node, this can run upwards of $150,000.
- Power Consumption: AI GPUs are power-hungry. An A100 80GB SXM4, for instance, has a Max Thermal Design Power (TDP) of 400W, while a PCIe version has a TDP of 300W. Data centers running multiple A100s incur substantial electricity bills, with AI servers consuming up to 10 times more power than traditional servers. Power consumption is a major operational expense.
- Cooling Infrastructure: The high heat output of A100 GPUs necessitates robust cooling systems. This adds to both the capital expenditure for specialized cooling solutions and ongoing operational costs for electricity to run these systems. Cooling can add 30-50% to operational expenses.
- Data Center Space and Racks: Physical space within a data center and the cost of server racks, power distribution units (PDUs), and other infrastructure elements contribute to TCO.
- Maintenance and Support: This includes the cost of IT staff for installation, configuration, monitoring, troubleshooting, and ongoing maintenance of the hardware and software stack. Server administration costs are a notable factor in TCO calculations.
- Software Licensing and Ecosystem: While NVIDIA provides a comprehensive software stack, some specialized tools or enterprise-level support contracts may incur additional costs.
- Depreciation and Obsolescence: GPUs, like all technology, depreciate over time. The rapid advancements in AI hardware mean that A100s, despite their current utility, will eventually be superseded by more powerful and efficient generations, impacting their resale value and requiring future upgrade cycles. Some models estimate a 25% annual depreciation rate for servers.
When comparing on-premise ownership with cloud rental, TCO calculations often show a breakeven point based on utilization. For instance, a Lambda Hyperplane-A100 server could be more cost-effective than an AWS p4d.24xlarge instance if utilized more than 17% of the time, assuming a 25% annual depreciation. If the value of the server depreciates to zero after one year, the breakeven point is around 56% utilization. For organizations with fluctuating workloads or uncertain long-term requirements, cloud providers typically offer a lower TCO by eliminating upfront capital, maintenance overhead, and depreciation risk, allowing users to pay only for actual usage. The ability to dynamically scale resources up or down in the cloud without significant sunk costs offers immense flexibility.
Conversely, for consistent, high-utilization workloads over several years, owning A100 hardware can eventually lead to lower long-term costs, especially when considering the continuous hourly charges of cloud platforms. However, this necessitates substantial capital investment and the infrastructure to support it. The decision ultimately boils down to a careful assessment of an organization’s specific workload patterns, financial capacity, and strategic objectives for AI development. For a detailed breakdown of TCO for AI inference processing comparing different GPUs, one might consult studies that highlight infrastructure and energy cost savings. For example, a study discussing the Qualcomm Cloud AI 100 versus the NVIDIA A100 for natural language processing BERT Large inferences provides insightful TCO analysis for rack-level infrastructure and energy costs. Qualcomm’s TCO analysis demonstrates how crucial these factors are in determining the overall economic viability of an AI accelerator deployment.
Conclusion
The NVIDIA A100 GPU has firmly established itself as a foundational technology for AI servers and data centers, offering a compelling blend of performance, versatility, and a mature ecosystem. In 2026, while newer architectures like Hopper and Blackwell push the boundaries of raw computational power, the A100 maintains its strategic importance as a cost-effective workhorse, particularly for large-scale inference, fine-tuning, and established production AI workloads. Its pricing, influenced by memory configuration, form factor, and market dynamics, has stabilized, making it an attractive option for organizations seeking a balance between capability and investment.
The choice between purchasing A100 GPUs and utilizing cloud rental models is a critical decision, with each offering distinct advantages. Direct ownership provides long-term cost savings for consistently high utilization, albeit with significant upfront capital and ongoing operational expenses for power, cooling, and maintenance. Cloud platforms, conversely, offer unparalleled flexibility, scalability, and reduced capital outlay, making them ideal for fluctuating workloads and rapid prototyping. A thorough Total Cost of Ownership (TCO) analysis, encompassing all direct and indirect expenses, is essential for informed decision-making.
As the AI landscape continues its rapid evolution, the A100’s enduring value lies in its proven reliability and its optimal price-to-performance ratio for a substantial segment of AI and HPC applications. For organizations that do not require the absolute bleeding edge offered by the latest generations, the A100 remains a smart, economically viable choice, empowering continued innovation in artificial intelligence.



