Revolutionary NVIDIA A100 GPU Features for Modern AI and Deep Learning
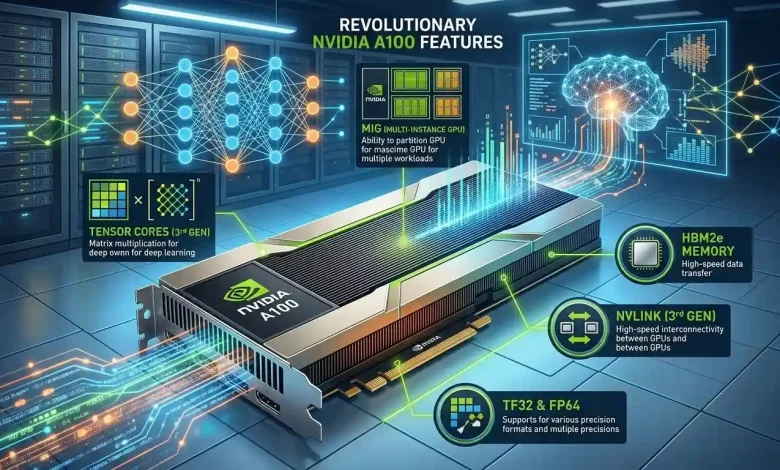
Table of Contents
NVIDIA A100 GPU stands as a monumental leap forward in the realm of accelerated computing, specifically engineered to tackle the most demanding challenges in artificial intelligence (AI), deep learning, and high-performance computing (HPC). Introduced with the Ampere architecture, the A100 represents a significant upgrade over its predecessors, offering up to 20 times higher performance compared to the NVIDIA Volta generation for various workloads. This advanced Tensor Core GPU acts as the core engine of the NVIDIA data center platform, providing unparalleled acceleration at every scale for elastic data centers. Its innovative features are not merely incremental improvements but rather foundational advancements that reshape the possibilities for researchers, data scientists, and engineers working with complex AI models and massive datasets. From groundbreaking Tensor Cores to the revolutionary Multi-Instance GPU (MIG) technology, the A100 is designed to optimize every facet of the AI and deep learning pipeline, from training colossal neural networks to delivering lightning-fast inference.
NVIDIA A100: A Paradigm Shift in AI and Deep Learning

The NVIDIA A100 Tensor Core GPU marks a pivotal moment in the evolution of AI and deep learning hardware. It is specifically designed to handle the escalating complexity and scale of modern AI models, which often involve billions of parameters and require immense computational power for both training and inference. The A100’s ability to deliver unprecedented acceleration has made it the workhorse for organizations engaged in serious AI and HPC work. Its architecture is built to accelerate a diverse range of workloads, from large-scale scientific simulations to real-time conversational AI, making it a versatile and indispensable tool for cutting-edge research and deployment.
The introduction of the A100 has allowed for significant reductions in training times, enabling researchers to iterate faster and bring innovative AI solutions to market more quickly. For instance, a training workload like BERT can be solved at scale in under a minute using 2,048 A100 GPUs, a world record for time to solution. This level of performance is critical for advancing fields such as natural language processing, image recognition, and autonomous systems, where models are continually growing in size and complexity. The A100’s power and efficiency ensure that AI applications can not only be developed but also deployed at scale, transforming industries and driving new discoveries.
Ampere Architecture: The Foundation of A100’s Prowess
At the very heart of the NVIDIA A100 GPU lies the NVIDIA Ampere architecture, a technological marvel that comprises over 54 billion transistors, making it one of the world’s largest 7-nanometer processors. This architecture is not merely about increasing transistor count; it’s a holistic design that brings together several innovations to deliver exceptional performance across AI, data analytics, and HPC workloads. The Ampere architecture focuses on maximizing compute utilization by pairing massive computational power with high-bandwidth memory and intelligent data transfer mechanisms.
Key architectural enhancements in Ampere include improvements in error and fault attribution, isolation, and containment, ensuring greater stability and reliability in multi-application or multi-user environments. The design also introduces asynchronous copy and barrier technologies, which enable more efficient data transfer and synchronization between computing tasks, ultimately reducing power consumption and enhancing overall performance. These foundational improvements allow the A100 to handle extremely complex and unpredictable workloads with remarkable efficiency and robustness.
Third-Generation Tensor Cores: Unleashing Unprecedented Performance
The NVIDIA A100 features third-generation Tensor Cores, which are specialized processing units specifically engineered to accelerate AI workloads dramatically. These cores are crucial for handling the complex matrix calculations that are fundamental to machine learning and deep learning tasks. The A100’s Tensor Cores introduce several groundbreaking advancements, significantly boosting performance over previous generations.
One of the most significant innovations is the introduction of Tensor Float 32 (TF32) precision. TF32 allows for up to 20 times higher AI compute performance compared to FP32 precision on NVIDIA Volta GPUs, often without requiring any code changes. This means developers can achieve substantial speedups in deep learning training while maintaining the accuracy typically associated with FP32. Furthermore, the A100’s Tensor Cores extend their power to HPC by supporting new precisions like FP64, delivering up to 2.5 times more compute than the previous generation for HPC applications. The A100 delivers 312 teraFLOPS (TFLOPS) of deep learning performance, translating to a 20x increase in Tensor FLOPS for training and 20x Tensor TOPS for inference compared to NVIDIA Volta GPUs. The A100 also supports BFLOAT16, FP16, INT8, and INT4 precisions, offering unmatched versatility for various deep learning inference and training tasks. The sparsity feature further enhances performance by up to 2x for sparse models, particularly benefiting AI inference but also improving model training.
Multi-Instance GPU (MIG): Maximizing Utilization and Flexibility

Multi-Instance GPU (MIG) is a revolutionary feature of the NVIDIA A100 that dramatically enhances GPU utilization and flexibility. It allows a single A100 GPU to be securely partitioned into as many as seven fully isolated GPU instances, each with its own dedicated high-bandwidth memory, cache, and compute cores. This hardware-level isolation ensures that workloads running on one instance do not interfere with others, providing predictable throughput and latency.
MIG is particularly beneficial for environments where diverse workloads need to share GPU resources, or when individual workloads do not fully saturate the GPU’s compute capacity. For instance, smaller deep learning models or early-stage development tasks can run on a subset of the GPU’s instances, allowing multiple users or applications to access breakthrough acceleration simultaneously. This capability optimizes utilization, expands access to accelerated computing resources, and provides guaranteed Quality of Service (QoS) for every job. With MIG, IT administrators can offer right-sized GPU acceleration, dynamically adjusting to shifting demands and maximizing the utility of every GPU in the data center, around the clock.
| Feature | NVIDIA A100 (40GB) | NVIDIA A100 (80GB) |
|---|---|---|
| GPU Architecture | Ampere | Ampere |
| Process Size | 7 nm | 7 nm |
| Transistors | 54.2 Billion | 54.2 Billion |
| CUDA Cores | 6,912 | 6,912 |
| Tensor Cores | 432 (3rd Gen) | 432 (3rd Gen) |
| Memory Capacity | 40 GB HBM2 | 80 GB HBM2e |
| Memory Bandwidth | 1.555 TB/s – 1.6 TB/s | 1.935 TB/s – 2 TB/s |
| TF32 Performance (Sparsity) | 312 TFLOPS (624 TFLOPS*) | 312 TFLOPS (624 TFLOPS*) |
| FP64 Performance (Tensor Core) | 19.5 TFLOPS | 19.5 TFLOPS |
| Max Power Consumption | 250 W | 300-400 W (SXM up to 500W) |
| Multi-Instance GPU (MIG) | Up to 7 instances (e.g., 7x 5GB) | Up to 7 instances (e.g., 7x 10GB) |
NVIDIA NVLink and NVSwitch: High-Bandwidth Interconnect
To support the immense computational power of the A100, NVIDIA has integrated its advanced NVLink and NVSwitch interconnect technologies. NVLink in the A100 delivers twice the throughput compared to the previous generation, providing 600 gigabytes per second (GB/sec) of GPU-to-GPU direct bandwidth. This is almost 10 times higher than PCIe Gen4, effectively eliminating bottlenecks in multi-GPU configurations.
When combined with NVIDIA NVSwitch, up to 16 A100 GPUs can be interconnected at this staggering speed of 600 GB/sec, unleashing the highest application performance possible on a single server. This high-bandwidth communication is essential for scaling large AI models and HPC applications across multiple GPUs, allowing them to act as a single, powerful computational unit. Systems like NVIDIA DGX A100 leverage NVLink and NVSwitch to achieve greater scalability for demanding AI and HPC workloads, making it possible to train models that were previously intractable due to communication overheads. This interconnected platform is a critical component of NVIDIA’s end-to-end data center solution, enabling researchers to tackle problems of unprecedented scale.
HBM2e Memory: Fueling Data-Intensive Workloads
Deep learning and AI workloads are inherently data-intensive, often requiring access to vast amounts of data at extremely high speeds. The NVIDIA A100 addresses this need with its High-Bandwidth Memory 2 (HBM2) and HBM2e variants. The A100 40GB model comes with 40 gigabytes (GB) of HBM2 memory, delivering a raw bandwidth of 1.555 TB/sec to 1.6 TB/sec. This offers a 1.7x higher memory bandwidth over the previous generation and ensures a dynamic random-access memory (DRAM) utilization efficiency of 95 percent.
For the most demanding applications, the A100 80GB configuration doubles the GPU memory to 80GB of HBM2e, debuting the world’s fastest memory bandwidth at over 2 terabytes per second (TB/s). This massive memory capacity and unprecedented bandwidth are crucial for running the largest models and datasets, especially in fields like deep learning recommendation models (DLRM) and complex scientific simulations. The increased on-chip memory, including a 40 MB Level 2 (L2) cache—seven times larger than the V100—further maximizes compute performance and data accessibility. This robust memory subsystem is vital for preventing data bottlenecks and ensuring that the powerful Tensor Cores are continuously fed with data, thereby maximizing overall system throughput.
Software Ecosystem and Deep Learning Frameworks
The hardware prowess of the NVIDIA A100 is fully realized through a comprehensive and optimized software ecosystem. NVIDIA has cultivated a rich suite of software, libraries, and tools that seamlessly integrate with popular deep learning frameworks, enabling developers and researchers to leverage the A100’s advanced capabilities with ease. The A100 supports over 2,000 GPU-accelerated applications, including every major deep learning framework such as TensorFlow, PyTorch, and MXNet.
NVIDIA’s software stack, including CUDA-X, TensorRT, and the RAPIDS suite of open-source libraries, provides a powerful edge in allowing applications to effectively utilize the GPU’s performance. NVIDIA AI Enterprise, an end-to-end, cloud-native software suite, further optimizes, certifies, and supports AI and data analytics workloads to run on NVIDIA-Certified Systems, facilitating rapid deployment and scaling in modern hybrid cloud environments. This extensive software support simplifies workflows, reduces development time, and ensures that the A100 is a ready-to-use platform for deep learning innovation, whether for training complex neural networks or deploying high-performance inference solutions. You can learn more about NVIDIA’s approach to accelerating AI at their official Deep Learning & AI page.
Real-World Applications and Impact
The NVIDIA A100 GPU has rapidly become an indispensable tool across a myriad of real-world applications, profoundly impacting various industries. Its unparalleled acceleration for deep learning and AI has enabled breakthroughs and efficiencies that were previously unattainable. In the realm of large language models (LLMs), the A100 has been instrumental in training colossal models like Meta’s Llama and Llama 2, processing terabytes of data to generate human-like responses and even outperforming proprietary models. Stability AI also utilized A100 GPUs for training its Stable Diffusion models, showcasing its capability in generative AI.
Beyond generative AI, the A100 is transforming scientific computing and data analytics. Shell, an international energy company, has employed A100 GPUs for high-performance computing (HPC) in oil and gas exploration, accelerating seismic imaging and reservoir simulations, which has significantly reduced simulation times from weeks to days. In healthcare, the A100 enhances diagnostic accuracy by powering sophisticated AI algorithms that analyze complex medical images with unprecedented precision, aiding in early disease detection like cancer. The A100 also accelerates multilingual content creation, powers super-fast LLM inference for companies like Perplexity, and plays a crucial role in 3D object reconstruction in deep learning systems. The versatility of the A100, combined with its ability to handle both large, complex workloads and smaller, diverse tasks through MIG, makes it a foundational component for advancing AI and HPC across numerous sectors.
Conclusion
The NVIDIA A100 GPU, powered by the innovative Ampere architecture, represents a transformative force in deep learning and AI. Its suite of advanced features, including the third-generation Tensor Cores with TF32 and FP64 precision, the revolutionary Multi-Instance GPU (MIG) technology, high-bandwidth NVLink interconnects, and leading-edge HBM2e memory, provides an unprecedented level of acceleration and flexibility. The A100’s ability to deliver up to 20 times higher performance over its predecessor, coupled with its robust software ecosystem, ensures that it remains at the forefront of AI and HPC development. As AI models continue to grow in complexity and data demands skyrocket, the NVIDIA A100 stands as a critical enabler, pushing the boundaries of what is possible in scientific discovery, technological innovation, and real-world application, making it the definitive platform for the next generation of intelligent machines.


