A6000 GPU Review: 10 Powerful Insights for 3D Rendering and AI Workloads
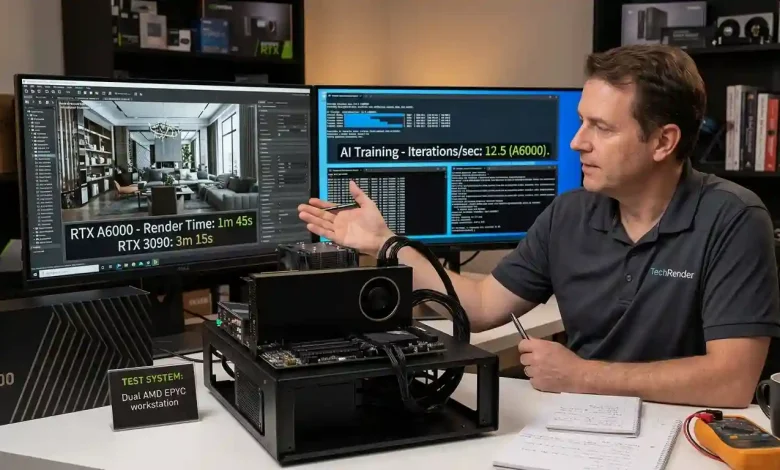
Table of Contents
The A6000 GPU Review for 3D Rendering and AI Workloads reveals a powerful contender in the professional graphics and compute landscape. NVIDIA’s RTX A6000, built on the Ampere architecture, is designed to meet the rigorous demands of professionals in fields such as digital content creation, scientific visualization, engineering, and artificial intelligence. This professional-grade GPU offers a compelling blend of high-performance rendering capabilities, massive memory capacity, and dedicated AI acceleration, making it a cornerstone for modern compute-intensive applications.
Introduction to the NVIDIA RTX A6000

The NVIDIA RTX A6000 stands as a testament to advanced visual computing, providing cutting-edge performance for desktop workstations. Launched on October 5th, 2020, this enthusiast-class professional graphics card quickly established itself as a go-to solution for tackling complex tasks that require extensive computational power and large datasets. It’s the successor to the Turing-powered Quadro RTX 8000, bringing significant advancements across the board. The RTX A6000 is not merely a graphics card; it’s a comprehensive visual computing GPU engineered to accelerate workflows in real-time ray tracing, AI-accelerated computing, and professional graphics rendering.
Designed for digital content creation, the NVIDIA RTX A6000 GPU offers nearly twice the performance of its predecessor, the RTX 8000 GPU. Its robust feature set and professional-grade reliability make it an indispensable tool for engineers, designers, researchers, and AI developers who demand uncompromised accuracy and consistent performance for mission-critical applications.
The Power of Ampere Architecture
At the heart of the NVIDIA RTX A6000 is the NVIDIA Ampere architecture, which represents a significant leap forward in GPU design. This architecture builds upon the major Streaming Multiprocessor (SM) enhancements from the Turing GPU, improving ray tracing operations, tensor matrix operations, and the concurrent execution of FP32 and INT32 operations. The Ampere architecture is specifically optimized for ray tracing, AI acceleration, and high-performance computing, making the A6000 exceptionally versatile.
Key architectural improvements include:
- Enhanced CUDA Cores: Ampere’s CUDA cores deliver up to 2X the single-precision floating-point (FP32) throughput compared to the previous generation. This translates to substantial performance boosts for graphics workflows like 3D model development and compute-intensive tasks such as desktop simulation for computer-aided engineering (CAE).
- Second-Generation RT Cores: These dedicated ray tracing engines provide incredible ray-traced rendering performance. The RTX A6000 is up to 2X faster in ray tracing compared to the previous generation, enabling users to render complex professional models with physically accurate shadows, reflections, and refractions for instant insight.
- Third-Generation Tensor Cores: Purpose-built for deep learning matrix arithmetic, these Tensor Cores accelerate neural network training and inferencing. They introduce Tensor Float 32 (TF32) precision, offering up to 5X the training throughput over Turing-based GPUs without requiring code modifications. Hardware support for structural sparsity further doubles the throughput for inferencing.
- PCIe Gen 4.0 Support: The A6000 supports PCI-Express Gen 4.0, which doubles the bandwidth potential compared to PCIe Gen 3.0, leading to faster data transfer speeds.
These advancements collectively contribute to the A6000’s ability to handle the most demanding professional workloads with unprecedented speed and efficiency.
3D Rendering Performance: A Deep Dive
For 3D rendering, the NVIDIA RTX A6000 is a formidable GPU, consistently delivering exceptional results across various rendering applications. Its combination of numerous CUDA cores, advanced RT Cores, and massive memory capacity makes it ideal for architects, product designers, animators, and visual effects artists.
In benchmarks, the RTX A6000 has shown remarkable improvements over its predecessors. For instance, in GPU render engines like OctaneRender, Redshift, and V-Ray, the A6000 can provide anywhere from 30% to a substantial 90% performance increase over the Quadro RTX 6000/8000. Specifically, in V-Ray 5 benchmarks, the RTX A6000 was found to be 2.32 times faster than the NVIDIA Quadro RTX 6000 in CUDA tests and 1.85 times faster in RTX tests. Similarly, in KeyShot 10 benchmarks, it outperformed the Quadro RTX 6000 by a factor of 1.97.
The 48GB of GDDR6 memory with Error-Correcting Code (ECC) is a significant advantage for 3D rendering professionals. This large memory footprint allows for handling massive datasets and complex models, which is crucial for high-fidelity architectural visualizations, intricate product designs, and detailed animation scenes. ECC memory ensures data integrity, which is vital for mission-critical applications where accuracy is paramount. The ability to scale up to 96GB of memory with NVLink by connecting two A6000 cards further enhances its capability to tackle extremely memory-intensive workloads.
Real-time visualization applications also benefit immensely. In Enscape, a large architectural scene of a museum (7.5GB) ran at a phenomenal 53 frames per second (FPS) on the RTX A6000, offering an incredibly smooth experience. This represents a 1.39 times faster performance than the NVIDIA Quadro RTX 6000 and 2.79 times faster than the NVIDIA Quadro RTX 4000. For workflows involving Unreal Engine, the A6000 delivered massive performance gains of around 60% over the Quadro RTX 6000/8000, with its large VRAM proving beneficial for emerging virtual production workflows.
AI and Deep Learning Workloads: Unmatched Acceleration

For AI and deep learning workloads, the NVIDIA RTX A6000 is a powerhouse, purpose-built to accelerate the most demanding tasks in machine learning, data science, and AI development. Its specialized Tensor Cores and substantial memory capacity make it an excellent choice for training and inference of complex neural networks.
The third-generation Tensor Cores are particularly noteworthy, introducing Tensor Float 32 (TF32) precision. This allows for up to 5X the training throughput compared to previous-generation GPUs, significantly accelerating AI and data science model training without requiring any code modifications. This is critical for researchers and developers working with large language models (LLMs) and advanced AI architectures.
The massive 48GB of ECC GDDR6 memory is a game-changer for AI. It enables professionals to work with larger models (including those with 30B+ parameters with quantization), bigger datasets, or higher batch sizes without encountering memory limitations. This is particularly beneficial for large language models, vision models, and complex scientific simulations.
Deep learning benchmarks highlight the A6000’s capabilities. In PyTorch, the A6000’s convnet “FP32” performance is approximately 1.5x faster than the RTX 2080 Ti, and its NLP “FP32” performance is around 3.0x faster. For TensorFlow convnet “FP32” performance, the A6000 is about 1.8x faster than the RTX 2080 Ti. While newer, more specialized AI cards like the A100 may offer higher performance in certain benchmarks, the A6000 provides a strong balance of professional graphics and AI compute.
The professional-grade reliability, including ECC memory and workstation drivers, ensures long training runs and high uptime, delivering consistent performance under heavy AI computational loads. This makes the A6000 ideal for both training and inference tasks in AI/ML projects.
Key Specifications and Technical Details
Understanding the core specifications of the NVIDIA RTX A6000 is essential to appreciate its capabilities:
The RTX A6000 is built on the GA102 graphics processor using an 8nm manufacturing process, containing 28.3 billion transistors. It features 10,752 NVIDIA CUDA Cores, 336 NVIDIA Tensor Cores, and 84 NVIDIA RT Cores, along with 112 ROPs.
Its memory subsystem is particularly robust, featuring 48GB of GDDR6 memory with ECC, connected via a 384-bit memory interface. This memory operates at 2000 MHz (16 Gbps effective), delivering up to 768 GB/s of memory bandwidth. For even more demanding scenarios, NVLink allows two A6000 cards to be linked, providing a combined 96GB of GDDR6 memory and up to 112 GB/s of bandwidth.
The GPU’s base clock runs at 1455 MHz, with a boost clock of 1860 MHz. It leverages 38.7 TFLOPS of single-precision performance (FP32), 75.6 TFLOPS of RT core performance, and 309.7 TFLOPS² of Tensor performance. The maximum power consumption (TDP) is rated at 300W, drawing power from an 8-pin EPS power connector. The card connects to the system via a PCI-Express 4.0 x16 interface. Display outputs include four DisplayPort 1.4a connectors, supporting up to four 5K monitors at 60Hz or dual 8K displays at 60Hz per card.
RTX A6000 vs. Gaming GPUs (e.g., RTX 4090)
While gaming GPUs like the RTX 4090 offer impressive raw performance, the NVIDIA RTX A6000 is fundamentally different, catering to professional workloads where stability, precision, and vast memory are paramount. The distinction lies in their design philosophy, target audience, and feature sets.
The RTX A6000 features 48GB of ECC GDDR6 memory, which is double the 24GB GDDR6X memory found in the RTX 4090. This massive VRAM capacity is critical for professionals working with extremely large datasets, complex 3D scenes, or high-resolution simulations that would easily exceed the memory limits of even high-end gaming cards. ECC memory, a hallmark of professional GPUs, corrects memory errors, ensuring data integrity and stability for mission-critical applications where even a single error could have significant consequences.
From a performance standpoint, the RTX 4090, based on the newer Ada Lovelace architecture, often surpasses the A6000 (Ampere architecture) in raw computational throughput, particularly in FP16 and FP32 operations. For instance, the RTX 4090 delivers 165 TFLOPS FP16 and 82.6 TFLOPS FP32, significantly higher than the A6000’s 38.7 TFLOPS for both FP16 and FP32. This disparity means the 4090 can complete deep learning iterations much faster for workloads where FP16 mixed precision dominates. The RTX 4090 also boasts a higher memory bandwidth at 1008 GB/s compared to the A6000’s 768 GB/s.
However, the A6000’s strengths lie in its professional-grade drivers, certified for a wide array of professional applications, ensuring compatibility, stability, and optimized performance. These drivers are crucial for applications in CAD, DCC, scientific visualization, and medical imaging. The A6000 is also designed for continuous, heavy workloads without thermal throttling, a common concern with some consumer-grade cards under prolonged stress. It also has a lower power consumption (300W TDP) compared to the RTX 4090 (450W TDP).
While a single RTX 4090 might offer superior speed in certain raw benchmarks for AI inference or some rendering tasks, the A6000’s larger VRAM and professional ecosystem make it indispensable for workflows that require:
- Handling models and datasets exceeding 24GB.
- Long training runs requiring high uptime and consistent performance.
- Applications demanding certified drivers and ECC memory for data integrity.
- Multi-GPU configurations leveraging NVLink for a unified memory space, which the RTX 4090 lacks.
Ultimately, the choice depends on the specific use case. For budget-conscious users prioritizing raw speed for smaller models or gaming, the RTX 4090 might be appealing. However, for professionals needing robust, reliable performance with vast memory and certified stability for complex 3D rendering and large-scale AI, the RTX A6000 remains the superior and more appropriate choice. For a detailed comparison of professional GPU performance, sources like Wikipedia’s article on Professional graphics cards provide valuable context on their distinct features and use cases.
Cost, Availability, and Value Proposition
The NVIDIA RTX A6000, being a professional-grade GPU, comes with a significantly higher price tag than its consumer counterparts. At launch, its price was around $4,649 USD. As of June 2026, market prices for the RTX A6000 can vary, with some listings around $4,849.99 for new units. The average price has fluctuated, showing a decreasing trend over 90 days but a neutral trend over 365 days, with an average of around $6112 to $5696 over different periods.
In cloud environments, the A6000 offers a compelling performance-to-cost ratio for GPU computing workflows, especially given its 48GB VRAM capacity and over 10,000 CUDA Cores. Hourly rental prices for an A6000 in the cloud can start as low as $0.33 to $0.35 per GPU-hour from providers like Runpod (community-cloud) or Thunder Compute (prototyping), making it accessible for projects that don’t require outright hardware purchase. However, prices can range up to $1.28 or even $1.89 from other providers, highlighting the importance of comparing services.
The value proposition of the RTX A6000 for professionals stems from several factors:
- Unmatched VRAM: The 48GB of ECC memory is a crucial differentiator, allowing users to handle the largest datasets and models that would be impossible on GPUs with less memory. This directly translates to fewer out-of-memory errors and the ability to work on more complex projects.
- Professional Reliability: ECC memory, robust cooling, and certified drivers ensure stable operation and data integrity, minimizing downtime and errors in critical workflows.
- Scalability with NVLink: The option to combine two A6000 cards via NVLink for a massive 96GB of unified memory and increased bandwidth is invaluable for extreme memory-intensive tasks.
- Optimized Performance for Pro Apps: The A6000 is specifically tuned and certified for professional applications, often delivering superior and more consistent performance in specialized software compared to gaming cards.
While consumer cards like the RTX 4090 might offer a lower entry price and higher raw TFLOPS in some specific benchmarks, the A6000’s combination of massive ECC VRAM, professional drivers, and workstation-grade reliability often makes it a more cost-effective long-term investment for businesses and individuals whose livelihoods depend on stable, accurate, and high-performance computing in 3D rendering and AI. The ability to rent A6000 instances in the cloud also democratizes access to this powerful hardware for smaller studios or individual researchers.
Conclusion
In conclusion, the NVIDIA RTX A6000 GPU remains a premier choice for professionals engaged in intensive 3D rendering and AI workloads. Its foundation on the Ampere architecture, coupled with 10,752 CUDA cores, 336 Tensor Cores, 84 RT Cores, and a colossal 48GB of ECC GDDR6 memory, equips it to handle the most demanding tasks with exceptional efficiency and reliability.
For 3D rendering, the A6000 delivers significant performance gains over previous generations, enabling faster real-time ray tracing, complex model development, and smooth interactive experiences in applications like V-Ray, OctaneRender, Redshift, and Unreal Engine. The vast memory is particularly advantageous for large scenes and high-fidelity visualizations.
In the realm of AI and deep learning, the A6000’s third-generation Tensor Cores with TF32 precision dramatically accelerate model training and inference. The 48GB of ECC VRAM is a critical asset for working with large language models, extensive datasets, and complex neural networks, ensuring both performance and data integrity.
While newer consumer GPUs like the RTX 4090 might offer higher raw TFLOPS in some metrics, the A6000 distinguishes itself through its professional-grade features: ECC memory, certified drivers, lower power consumption, superior multi-GPU scaling via NVLink, and unwavering stability under sustained heavy loads. These attributes make it an indispensable tool for enterprises and professionals where precision, uptime, and the ability to tackle memory-intensive tasks are non-negotiable. The NVIDIA RTX A6000 continues to define the benchmark for high-performance visual computing and AI acceleration in the professional workstation segment.